
Erfahren Sie, wie Sie Daten in Cognition hochladen.
Viele GenAI-Agenten verwenden Retrieval Augmented Generation (RAG), um Wissen aus Dokumenten und unstrukturierten Daten zu gewinnen. Da Wissen oft in PDF-Dateien gespeichert wird, können Sie unsere ETL-Pipeline verwenden, um die PDF-Datei in ein für LLM zugänglicheres Markdown-Format zu konvertieren. Darüber hinaus wird es zu kleineren RAG-fähigen Inhaltsblöcken verarbeitet und kann dann über einen optionalen Export in Refinery der Kern AI-Plattform gespeichert werden. Dieser Abschnitt ist für das Hochladen von Daten vorgesehen. Weitere Informationen zu den Vorgängen finden Sie in der Abschnitt „Dokumentation zur Datenverarbeitung“.
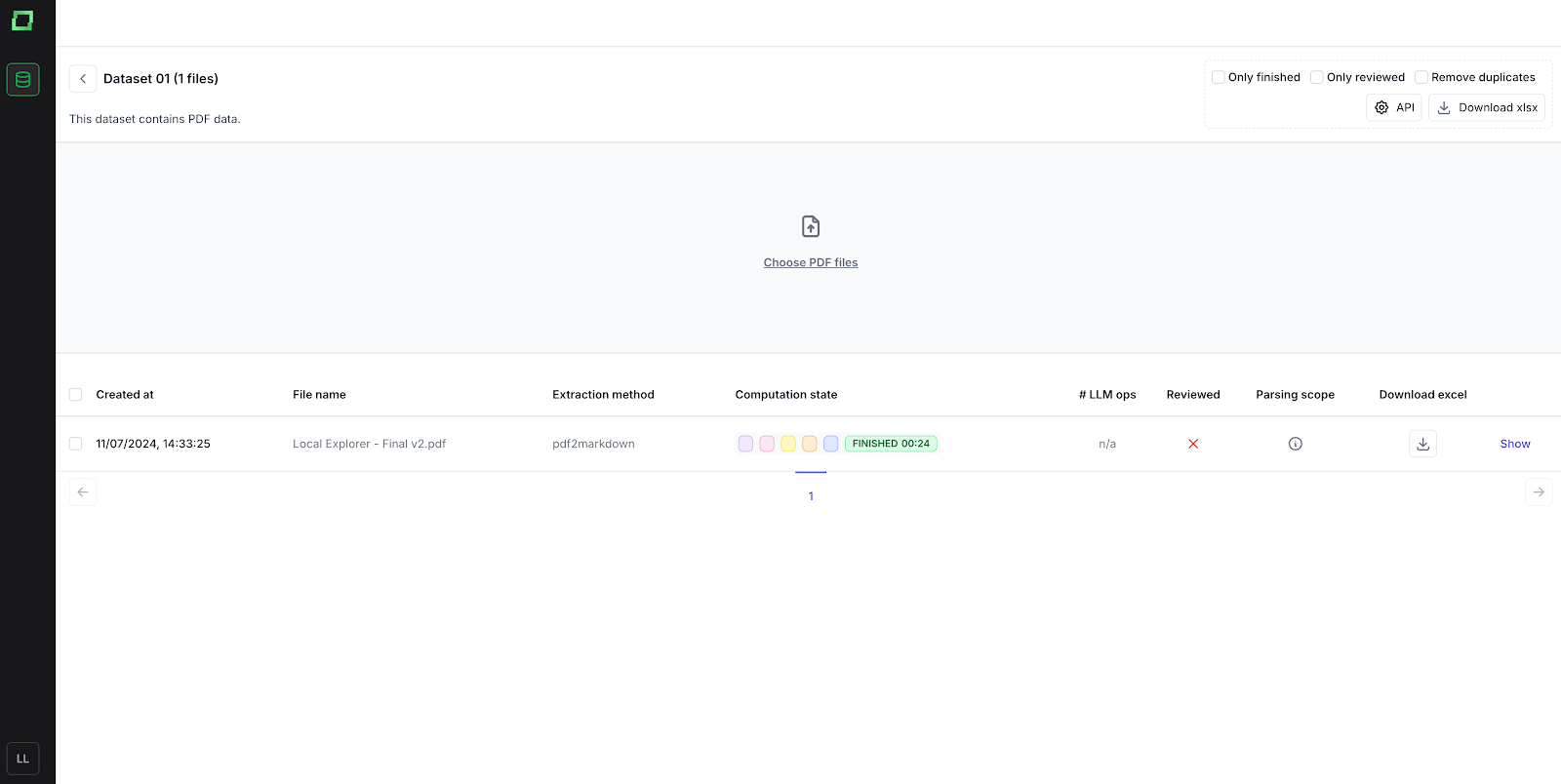
Wenn du deine Daten hochlädst, durchläuft sie mehrere Phasen:
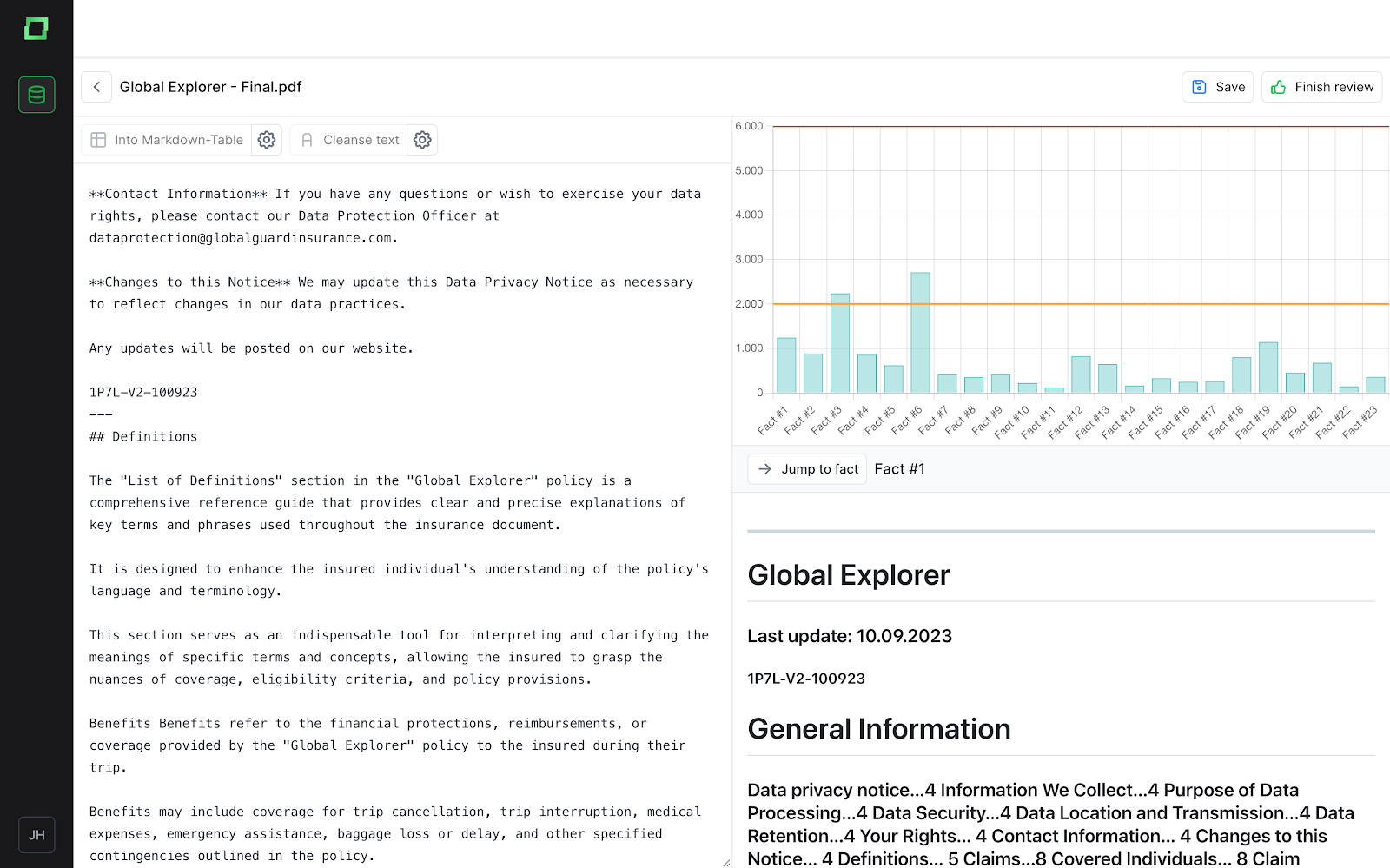
Sie können analysieren, wie die Markdown-Chunks aussehen und wie sie derzeit gespeichert werden. Auf der rechten Seite können Sie auch sehen, wie lang die einzelnen Fakten sind, sowie eine Best-Practice-Cutoff-Länge.
Wenn ein Text zusätzliche Änderungen benötigt, können die Verbesserungen direkt im Texteditor oder mit einer der Optionen „In Markdown-Table“ (um ihn in eine Markdown-Tabelle zu konvertieren) oder „Text reinigen“ (um den Text von Sonderzeichen oder Text zu reinigen, der nicht dem Inhalt entspricht) vorgenommen werden. Sobald die Analyse/Überprüfung abgeschlossen ist, kann dies einfach mit der Schaltfläche „Überprüfung beenden“ markiert werden. Alle Dateien, nur überprüfte Dateien oder jede Datei einzeln können in einem Excel-Formular heruntergeladen werden. Darüber hinaus kann der Text weiter in Abschnitte aufgeteilt werden, indem dem Text drei Bindestriche (- - -) hinzugefügt werden. Weitere Informationen zu verloren gegangenen Informationen und zur Bereinigung von Daten finden Sie im Abschnitt „Dokumentation zur Datenverarbeitung“.
Eine weitere Option zum Ausführen der ETL-Pipeline ist die API, mit der Sie die Pipeline ausführen und Ergebnisse sammeln können, ohne die Benutzeroberfläche der Anwendung zu verwenden. Der bereitgestellte Codeausschnitt erfordert benutzerdefinierte Konfigurationen, einschließlich des API-Schlüssels/Tokens, des Dateipfads und der Extraktionsmethode. Token können innerhalb der Anwendung mit anpassbaren Ablaufoptionen (1 Monat, 3 Monate oder nie) generiert werden. Es ist wichtig, den Token-Wert sicher zu speichern, da er nach der Erstellung nicht in der Tabelle sichtbar ist.
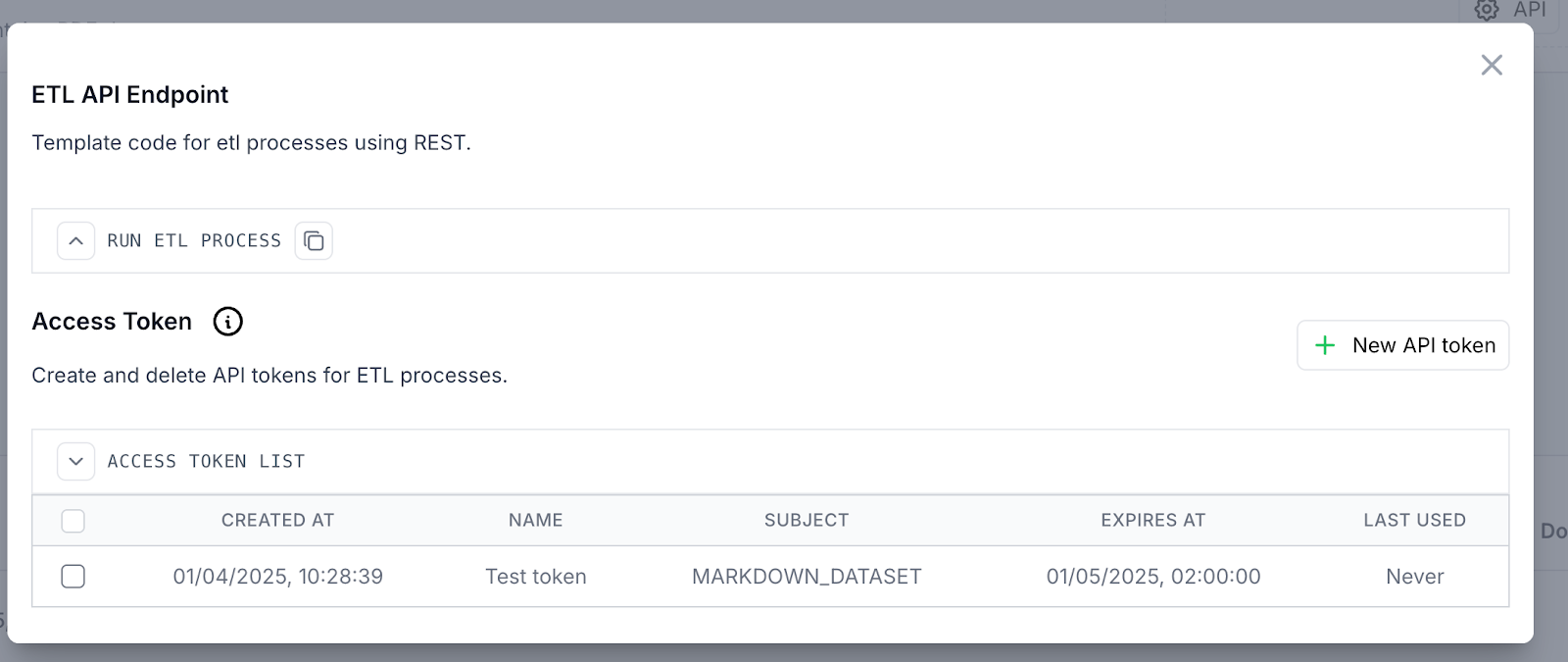
Token werden entweder der ETL-Ebene (Betreff MARKDOWN_DATASET) oder der Projektebene (Betreff PROJECT) zugewiesen, wobei jedes Token einen definierten Umfang hat. ETL-Token werden ausschließlich innerhalb des ETL-Prozesses verwendet, während Projekt-Token auf die Projektebene beschränkt sind.
Um die Leistung und Effizienz der Dateiverarbeitung zu verbessern, führt die Anwendung einen Caching-Mechanismus ein, der auf SHA-256-Hashing basiert. Durch das Zwischenspeichern bei jedem kritischen Schritt — vom ersten Datei-Upload über die Extraktion bis hin zur endgültigen Transformation — wird sichergestellt, dass nur neue und einzigartige Operationen der Dateiverarbeitung ausgeführt werden.