
See how to upload data into cognition.
Many GenAI agents use Retrieval Augmented Generation (RAG) to obtain knowledge from documents and unstructured data. Since knowledge is often stored in PDFs, you can use our ETL pipeline to convert the PDF file into a more LLM accessible markdown format. Furthermore, it will be processed into smaller RAG-ready chunks of content and will be ready to be stored in Refinery of the Kern AI platform through an optional export. This section is indented for the upload of data, but more information about the processes are described in the Data Processing Documentation Section.
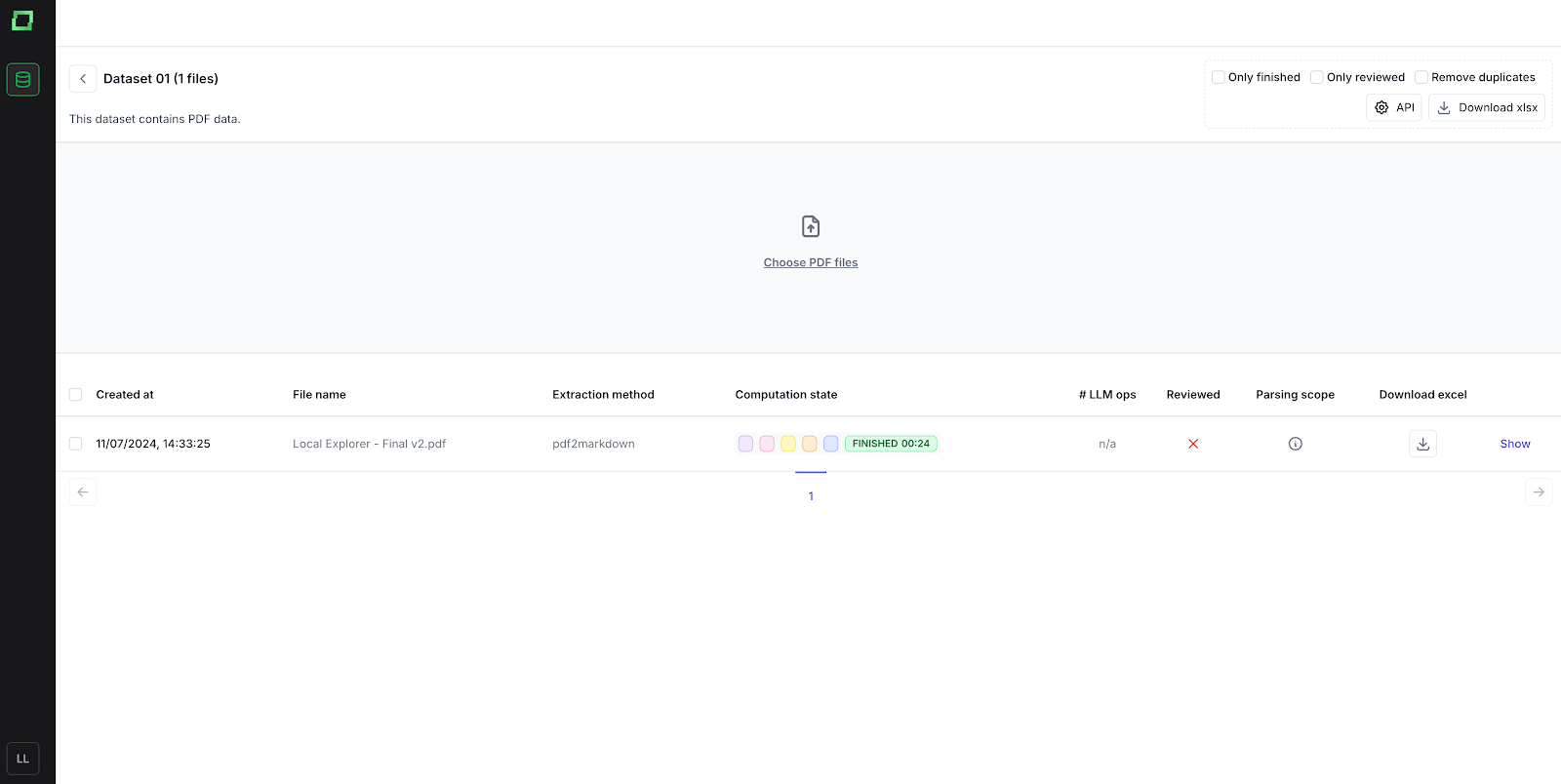
If you upload your data, it will run through multiple stages:
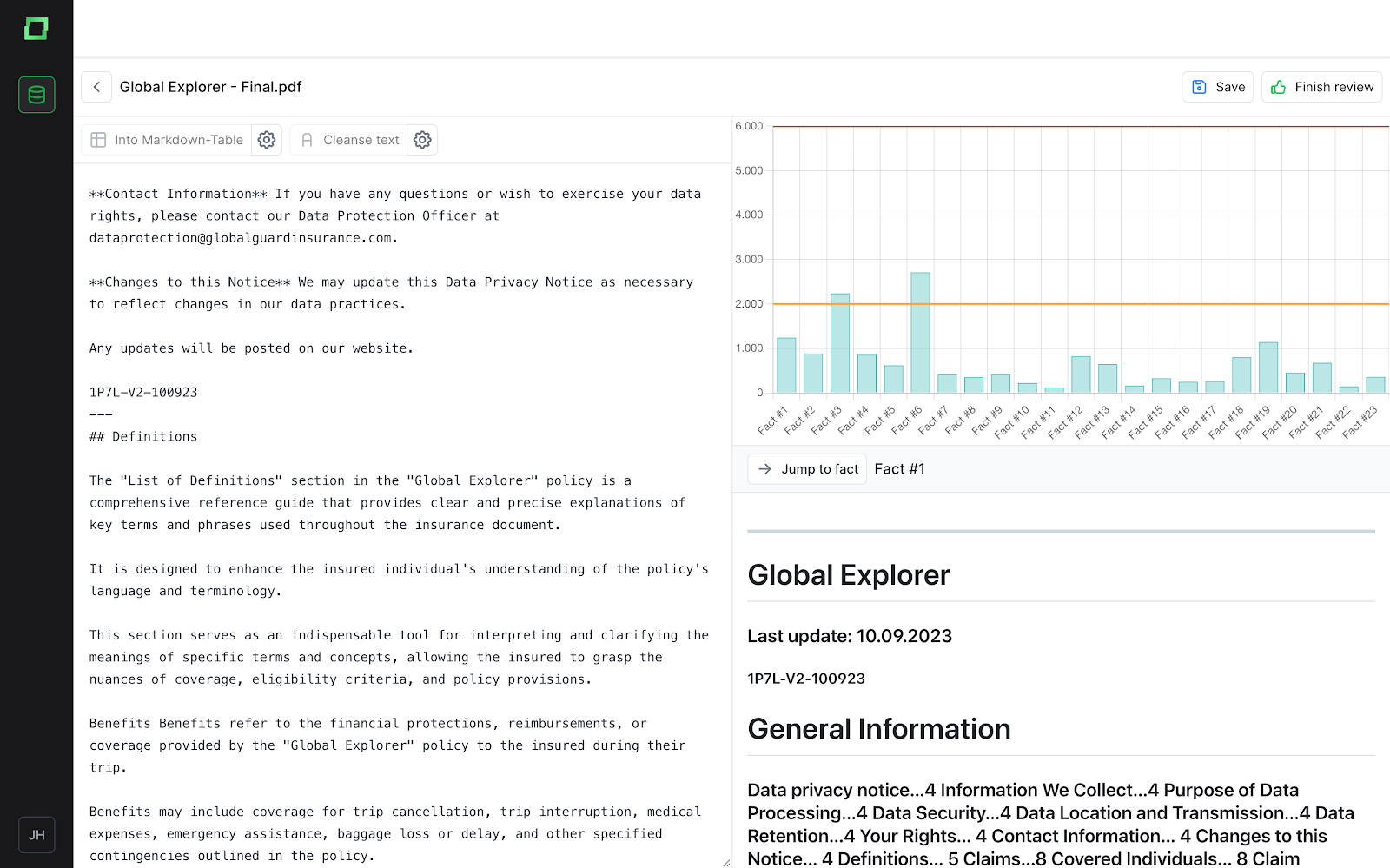
You can analyze what the Markdown chunks look like and how they are currently being stored. On the rightern side, you can also see how long each chunked fact is, as well as a best practice cutoff length.
If some text needs additional changes, the improvements can be done directly in the text editor or with the use of one of the options ‘Into Markdown-Table’ (to convert it in a markdown table) or ‘Cleanse Text’ (to clean the text from special characters or text that does not correspond to the content). Once the analyzation/review is done, this can be easily marked with the ‘Finish review’ button. All files, only reviewed files, or each file separately can be downloaded in an Excel form. Additionally, the text can be further split into chunks by adding three dashes (- - -) to the text. More about lost information and cleaning data in the Data Processing Documentation Section.
Another option for running the ETL pipeline is through the API, which allows you to execute the pipeline and collect results without using the application's UI. The provided code snippet requires custom configurations, including the API key/token, file path, and extraction method. Tokens can be generated within the application, with customizable expiration options (1 month, 3 months, or never). It is important to securely store the token value, as it will not be visible in the table once created.
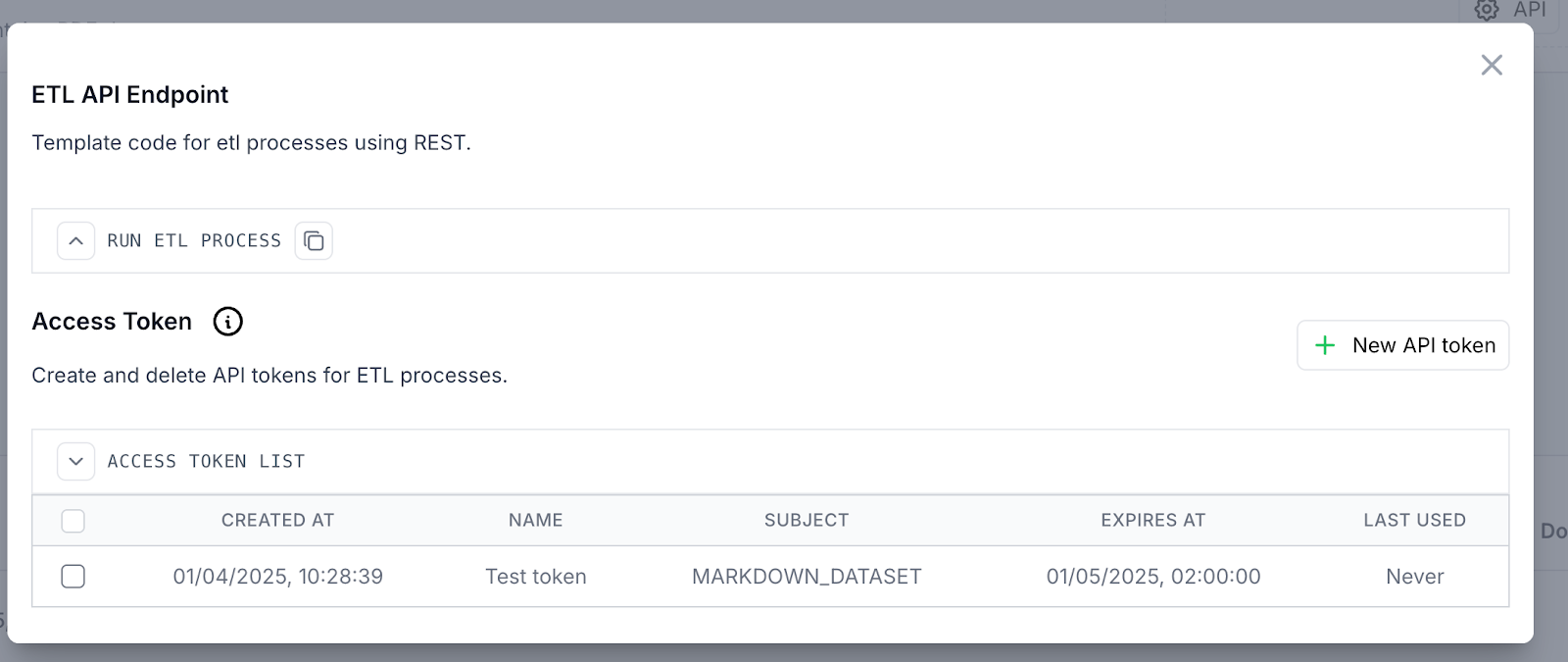
Tokens are assigned to either the ETL level (subject MARKDOWN_DATASET) or the project level (subject PROJECT), with each having a defined scope. ETL tokens are exclusively used within the ETL process, while project tokens are restricted to the project level.
To enhance the performance and efficiency of file processing, the application introduces a caching mechanism based on SHA-256 hashing. By caching at every critical step—from the initial file upload to the extraction and the final transformation— it is insured that only new and unique operations of the file processing are performed.