
Fügen Sie Einbettungen direkt aus OpenAI, Azure, Hugging Face, Cohere oder anderen Einbettungen hinzu.
Je nach Ihrer Aufgabe können Sie als Erstes eine (oder mehrere) Einbettungen für Ihre Daten auswählen. Wenn Sie mit Einbettungen noch nicht vertraut sind, schauen Sie sich unbedingt [unseren Blog] (https://www.kern.ai/company/blog) an oder schauen Sie sich andere Ressourcen wie [diese] (https://www.kdnuggets.com/2021/11/guide-word-embedding-techniques-nlp.html) an.
Um eine zu erstellen, klicken Sie auf der Seite mit den Projekteinstellungen auf „Einbettung generieren“. Es öffnet sich ein Modal, in dem Sie nach den folgenden Informationen gefragt werden: - `Zielattribute`: Wenn Sie mehrere Textattribute haben, ist es sinnvoll, die Einbettungen für sie Schritt für Schritt zu berechnen. Hier kannst du das Attribut wählen, das du codieren möchtest. - `platform`: Mit dieser Option kannst du zwischen lokal generierten Einbettungen von HuggingFace (z. B. BERT) oder Python (z. B. Bag-of-Words) oder Einbettungen von Drittanbietern wie OpenAI (z. B. GPT) oder Cohere wählen. - `Granularität`: Ihr könnt beide die Einbettungen für das gesamte Attribut berechnen (z. B. den vollständigen Satz/Absatz) oder für jedes Token. Die letztere Option ist für Extraktionsaufgaben hilfreich, wohingegen Attributeinbettungen Ihnen sowohl bei Klassifikationsaufgaben als auch bei [neuronaler Suche] (/refinery/neural-search) helfen. Wir empfehlen, immer mit Einbettungen auf Attributebene zu beginnen. - `model`: Dies definiert das zu verwendende Modell. Für HuggingFace kannst du aus den empfohlenen Optionen wählen oder eine beliebige Konfigurationszeichenfolge eingeben (z. B. `kernai/stock-news-distilbert`).
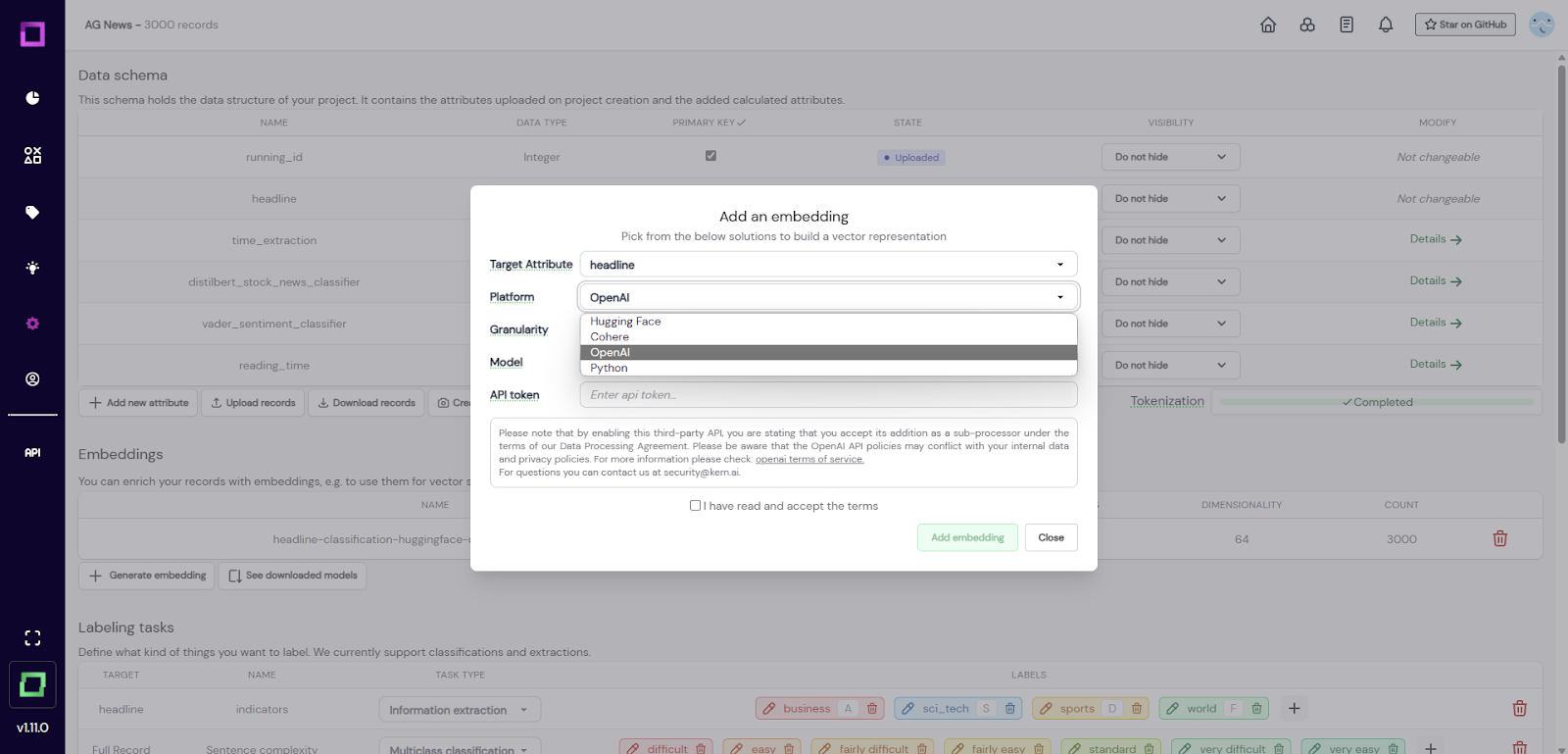
Abb. 1: Screenshot der Seite mit den Projekteinstellungen, auf der der Benutzer eine neue Einbettung hinzufügen möchte. Für Drittanbieter müssen Sie einen API-Schlüssel angeben und deren Nutzungsbedingungen akzeptieren. In der verwalteten Version wird die Erstellung der Einbettung auf einer GPU-beschleunigten Instanz berechnet. Im Allgemeinen kann dieser Vorgang einige Zeit in Anspruch nehmen, sodass es an der Zeit ist, einen heißen Kaffee zu trinken. ☕ Um Speicherplatz zu sparen, werden die Einbettungen mithilfe von PCA auf 64 Dimensionen reduziert. In unseren Experimenten hatte dies keine signifikanten Auswirkungen auf die Leistung der neuronalen Suche, auf aktive Lernende oder auf andere Funktionen der Raffinerie, die mit der Einbettung zu tun haben. Du kannst mehr darüber [hier] lesen (https://www.sbert.net/examples/training/distillation/README.html#dimensionality-reduction). Sobald die Berechnung abgeschlossen ist, ist die Einbettung für aktives Lernen nutzbar (und im Fall von Einbettungen auf Attributebene für [neuronale Suche] (/refinery/neural-search)).
Wenn Sie die verwaltete Version von Refinery verwenden, können Sie häufig verwendete Modelle herunterladen, sodass sie nicht jedes Mal, wenn Sie sie verwenden, aus dem Gesicht gezogen werden müssen. Sie sind dann weltweit für deinen Workspace verfügbar, nicht nur für ein einzelnes Projekt. Gehe dazu auf eine Seite mit den Projekteinstellungen und suche unter den Einbettungen nach der Schaltfläche „Heruntergeladene Modelle anzeigen“. Füge dort einfach ein neues Modell hinzu. Der gesamte Vorgang ist in Abb. 2 dargestellt.
Abb. 2: GIF des Benutzers, der ein Huggingface-Modell zu den heruntergeladenen Modellen hinzufügt.