
Verwenden Sie die Datensatz-IDE, um schnell eine einzelne Datensatzstruktur zu analysieren.
Mit der Datensatz-IDE können Sie sich bestimmte Datensätze aus programmatischer Sicht ansehen. Von hier aus können Sie Labeling-Funktionen prototypisieren, die SpacY Doc-Struktur Ihrer Textattribute erkunden oder eine neue Regex testen.
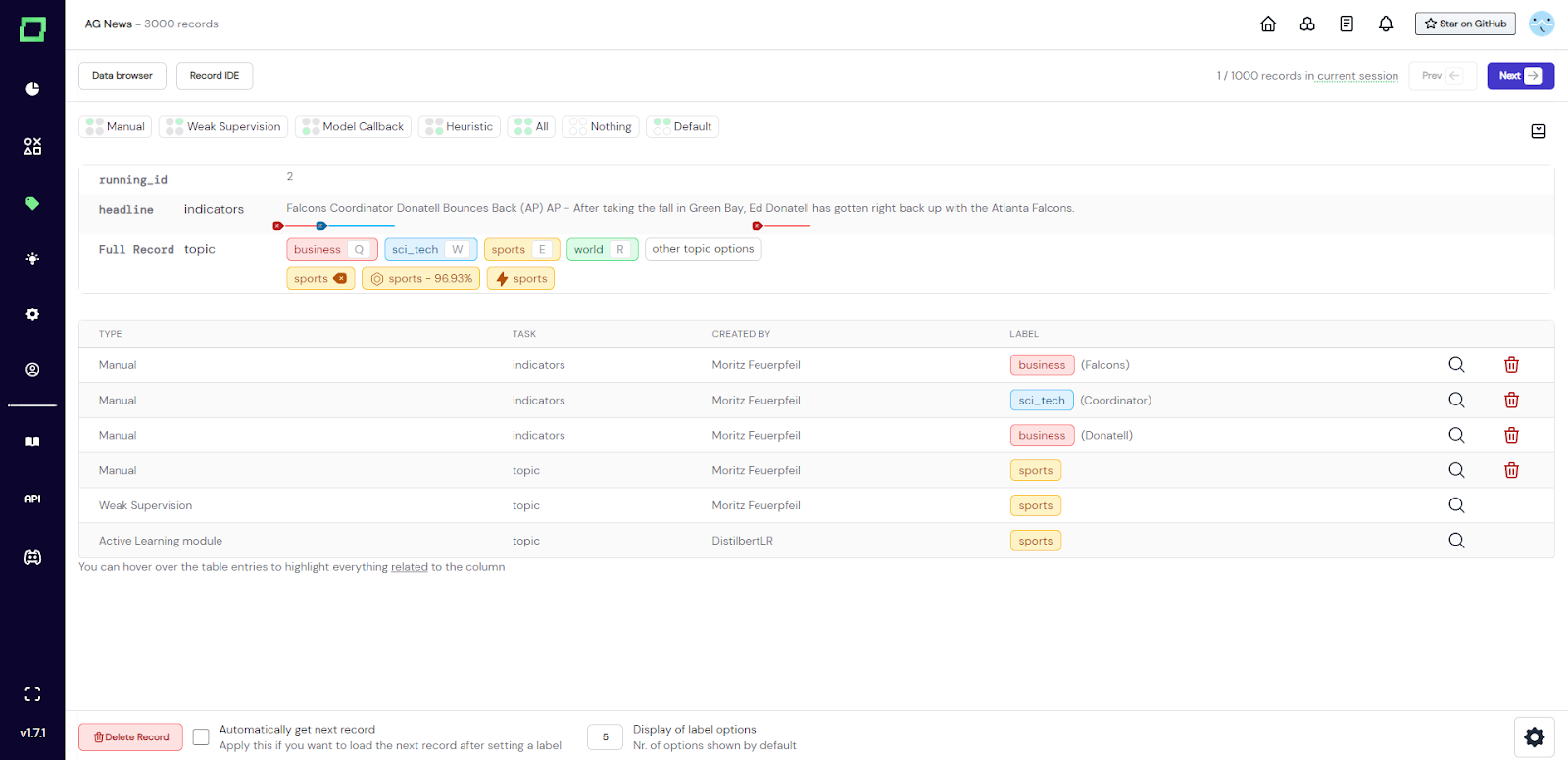
Abb. 1: Screenshot der Labeling-Ansicht. Sie können von hier aus auf die Datensatz-IDE zugreifen, indem Sie auf die zweite Schaltfläche von links oben klicken.
Wie in Abb. 2 zu sehen ist, ist die Datensatz-IDE in zwei Hälften geteilt und besteht aus einem Code-Editor auf der linken Seite und einer Output-Shell auf der rechten Seite. Es gibt eine voreingestellte Variable namens `record`. Dabei handelt es sich um ein einzelnes Wörterbuch, in dem die Schlüssel die Namen der Attribute sind (dasselbe Format wie die Eingabe einer [Labeling-Funktion] (/refinery/heuristics #labeling -functions)). Sie können diese Variable verwenden, um mit dem Datensatz zu interagieren, der gerade angezeigt wird.
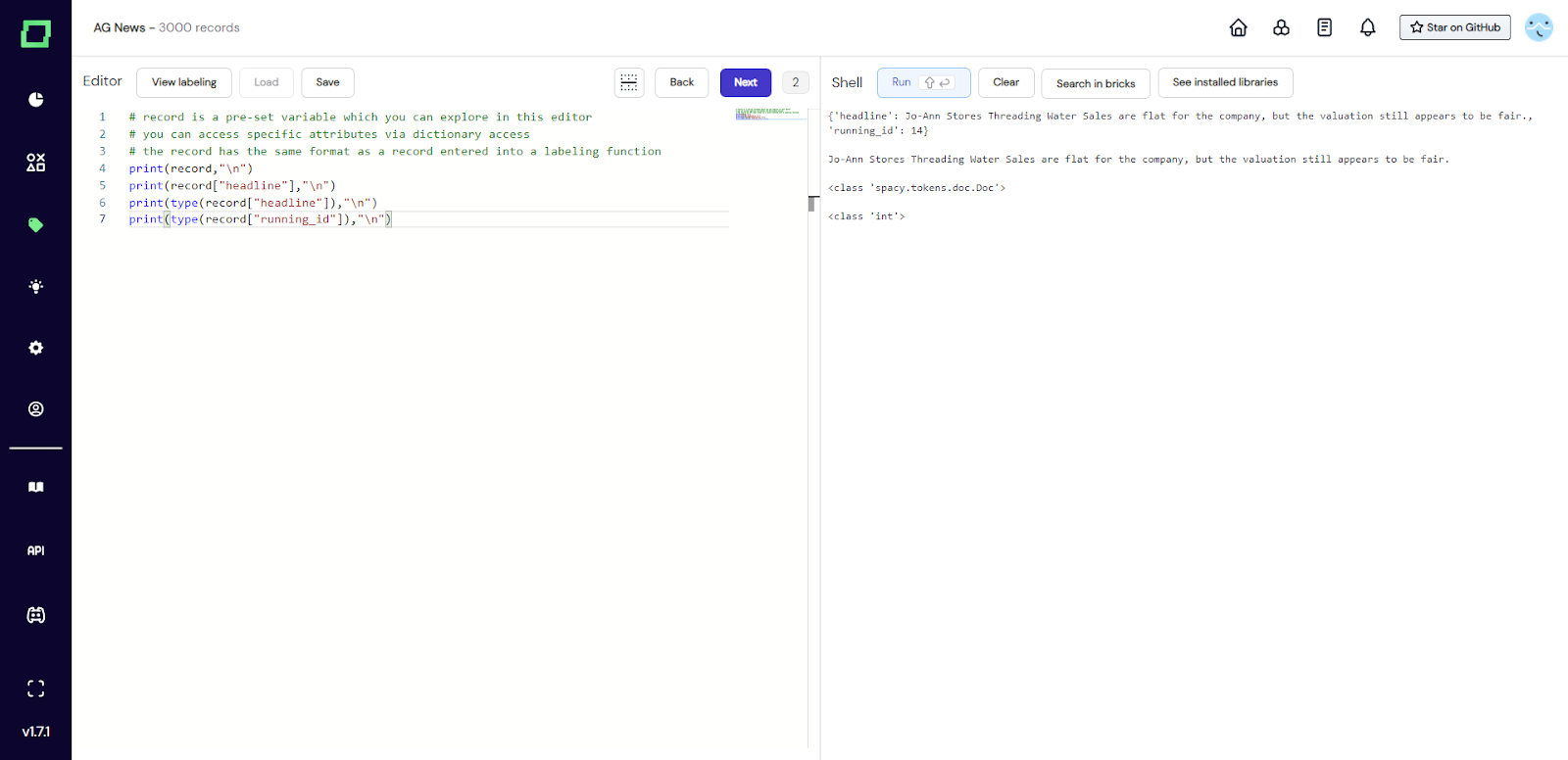
Abb. 2: Screenshot der Record-IDE. Der Benutzer druckte die Datensatzvariable und einige Informationen zu ihren Attributen aus. Die Codeeingabe befindet sich auf der linken Seite und die gedruckte Ausgabe befindet sich auf der rechten Seite.
Mit der Schaltfläche ganz rechts gelangen Sie zu den installierten Bibliotheken, die Sie importieren und in dieser IDE verwenden können. Sie sind identisch mit denen für die Labeling-Funktionen, um das Prototyping von Labelfunktionen zu ermöglichen.
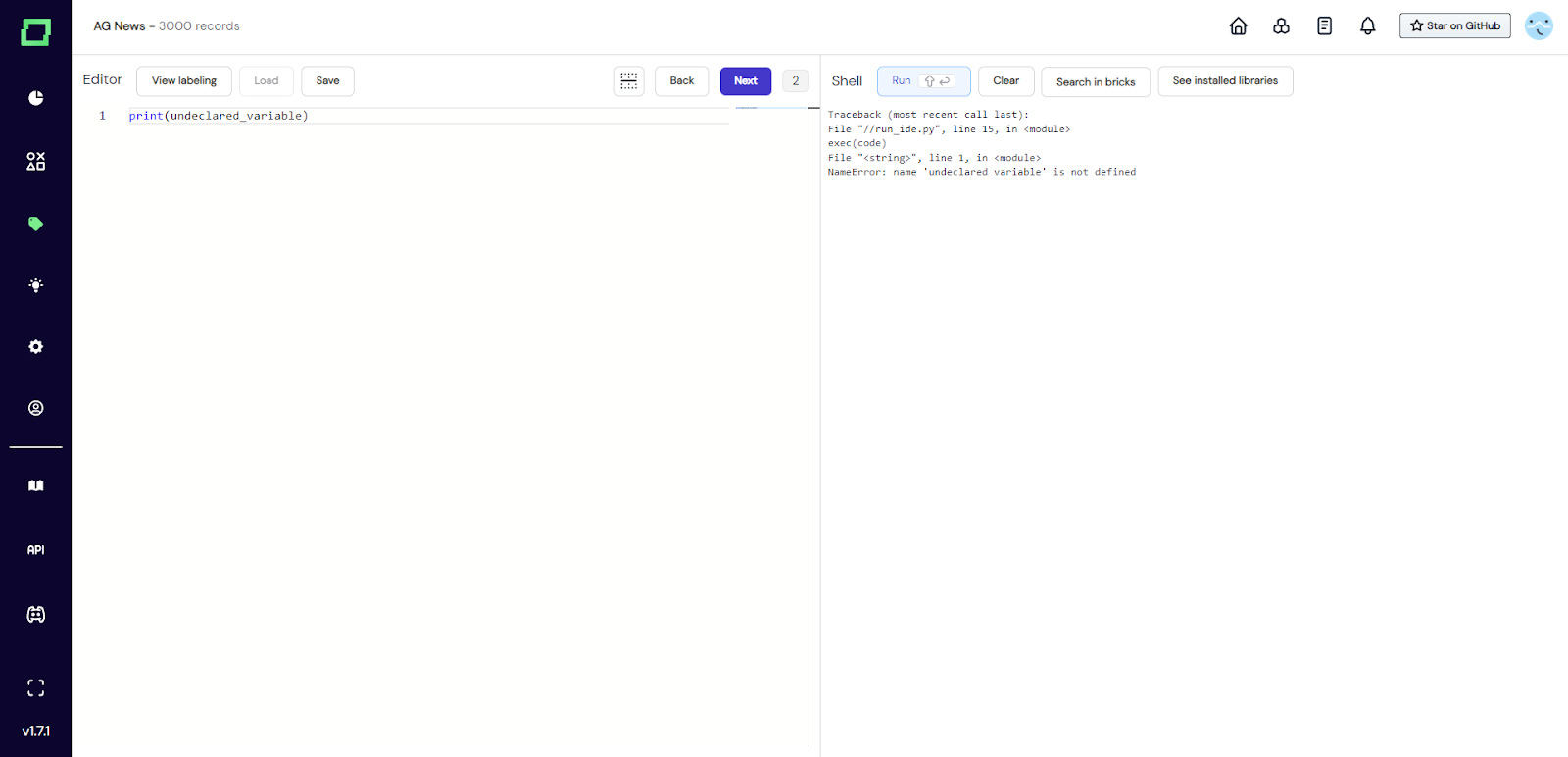
Abb. 3: Screenshot der Datensatz-IDE, in der ein Benutzer ungültigen Code geschrieben hat. Der Fehler kann in der Output-Shell überprüft werden.
Um den Code auszuführen, können Sie entweder SHIFT + ENTER auf Ihrer Tastatur drücken oder die „Run“ -Taste direkt über der Output-Shell drücken. Es gibt auch eine integrierte Navigation (Schaltflächen „Zurück“ und „Weiter“ über dem Code-Editor), sodass Sie Ihren Code an allen Datensätzen der aktuellen Labeling-Sitzung ausprobieren können. Nachdem Sie zum nächsten oder vorherigen Datensatz navigiert haben, wird Ihr Code automatisch ausgeführt. Im Allgemeinen empfehlen wir, vorsichtig zu sein, wenn Sie mit ratenbegrenzten APIs in der Datensatz-IDE experimentieren.
Genau wie die [Bricks-Integration] (/refinery/bricks-integration) für die Kennzeichnung von Funktionen können Sie auch vorgefertigte Bricks-Module in der Record-IDE für das Prototyping und Testen verwenden. Klicken Sie auf die Schaltfläche „In Bricks suchen“ über der Output-Shell und folgen Sie der Integration. Der generierte Code wird nach Abschluss der Integration automatisch ausgeführt.
Code wird nur innerhalb einer IDE-Sitzung mit einem einzelnen Datensatz automatisch gespeichert. Das heißt, wenn Sie die Seite verlassen, wird der Code auf die Standardeinstellung `print (record) `zurückgesetzt. Wenn Sie jedoch einen Prototyp für eine Beschriftungsfunktion entwickelt haben, die Sie für später speichern möchten, können Sie dies tun, indem Sie auf die Schaltfläche „Speichern“ über dem Code-Editor klicken. Dadurch wird der Code in Ihrem lokalen Browserspeicher gespeichert, der nur einen einzigen Eintrag enthält. Derzeit gibt es keine Rückmeldung darüber, ob der Code gespeichert wurde oder nicht, aber machen Sie sich darüber keine Gedanken, da es sich um einen lokalen Vorgang im Browser handelt, bei dem keine Kommunikation mit Diensten stattfindet, die fehlschlagen könnten.
Abb. 4: GIF des Benutzers, der die Bricks-Integration demonstriert und dann den generierten Code speichert, um in einer späteren Sitzung wieder darauf zuzugreifen.