
Erfahren Sie, wie Sie Projekte in einer Raffinerie erstellen und Daten hochladen
Um ein neues Projekt zu starten, hast du zwei Möglichkeiten: Entweder du erstellst ein Projekt von Grund auf neu (Button „Neues Projekt“) oder du hast bereits ein Projekt, das irgendwann als Snapshot exportiert wurde und an dem du weiterarbeiten möchtest (Schaltfläche „Snapshot importieren“).
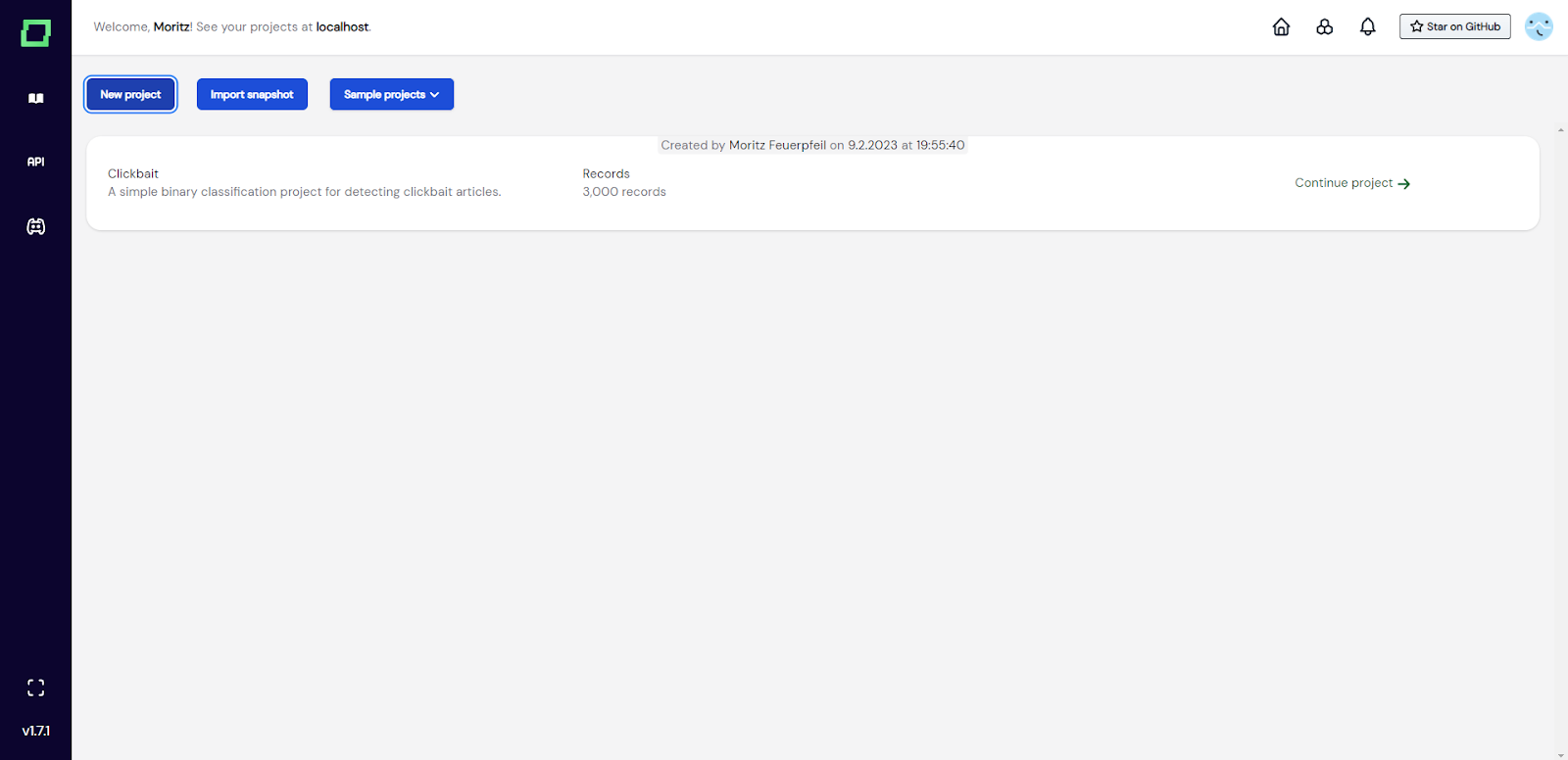
Abb. 1: Screenshot der Raffinerie-Homepage, auf der der Benutzer bereits ein Projekt hat (von unserem [quickstart] (/refinery/quickstart)) und ein weiteres hinzufügen möchte.
Da für die zweite Option keine weiteren Informationen erforderlich sind (Sie ziehen einfach den Projektexport per Drag-and-Drop), werden wir näher darauf eingehen, wie Sie mit einem brandneuen Projekt beginnen können.
Ein Projekt kann nicht ohne Daten erstellt werden, weshalb Sie den gewünschten Datensatz griffbereit haben sollten. Wenn Sie sich nicht sicher sind, ob Ihre Daten den Anforderungen der Raffinerie entsprechen, sehen Sie sich bitte den Abschnitt mit den Datenanforderungen auf dieser Seite an.
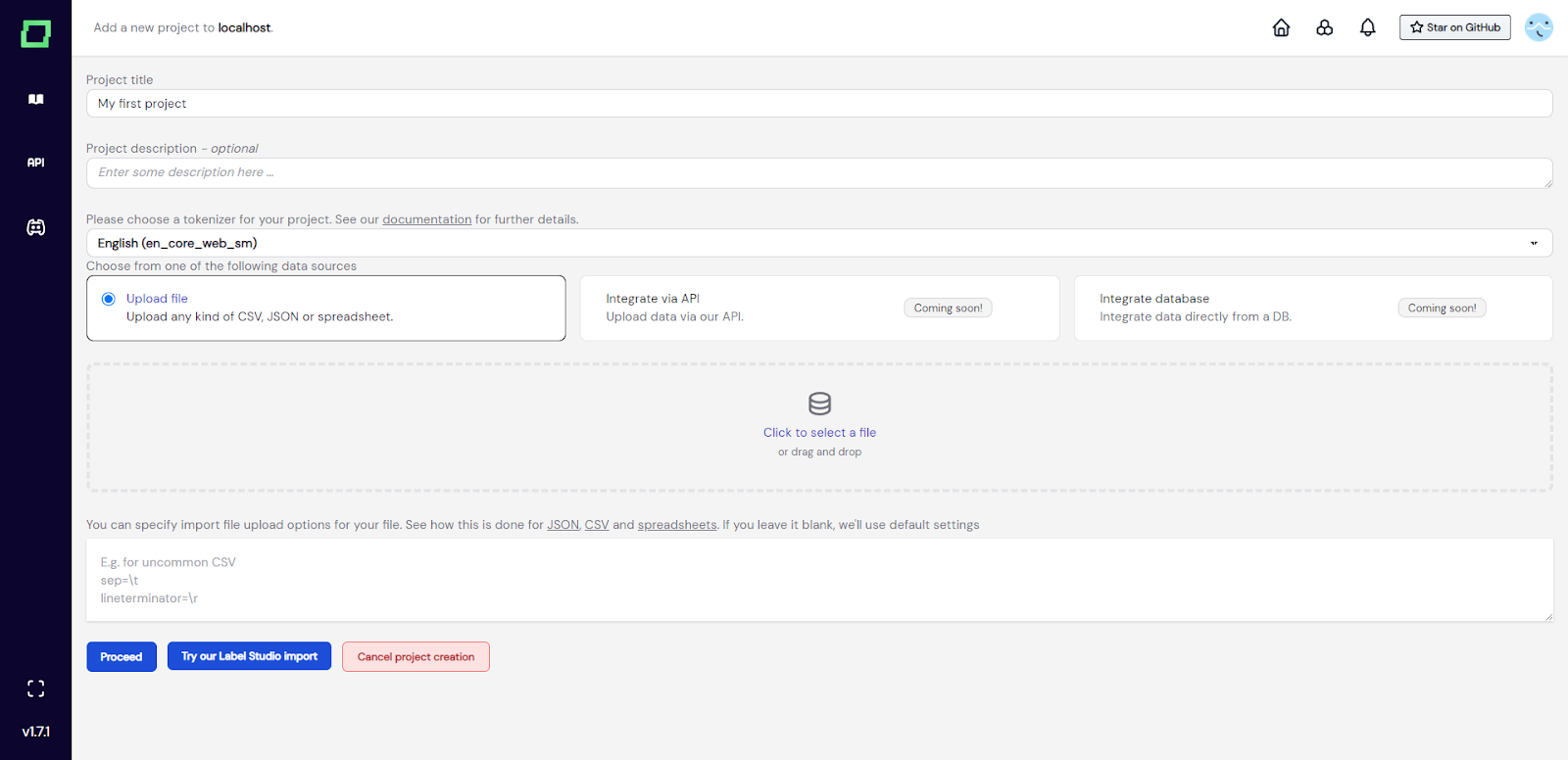
Abb. 2: Screenshot der Seite zur Projekterstellung.
Vorerst gehen wir davon aus, dass Sie Ihre Daten bereit haben und ein Projekt damit erstellen möchten. Der Arbeitsablauf ist wirklich unkompliziert, da Sie einfach einen Titel und eine Beschreibung eingeben, den richtigen Tokenizer für Ihre Textdaten auswählen und eine Datei hochladen. Der Tokenizer dient in Raffinerien zwei Zwecken: - Definition atomarer Informationseinheiten in Ihren Texten, die für das Span-Labeling benötigt werden - Vorberechnung wertvoller Metadaten für jedes Token, die dann für Labeling-Funktionen und andere Aufgaben zur Verfügung stehen Wenn Sie einen `Spacy`-Tokenizer benötigen, der in der Auswahl nicht verfügbar ist, fügen Sie ihn bitte zu Ihrer [Konfigurationsseite] hinzu (/refinery/configuration-page). Nachdem Sie es hinzugefügt haben, erstellen Sie ein neues Projekt und es sollte verfügbar sein. Derzeit unterstützt die Raffinerie das Hochladen von Daten per Datei. In naher Zukunft wird die Raffinerie auch Uploads über API (und Python-SDK) und Datenbankintegrationen ermöglichen.
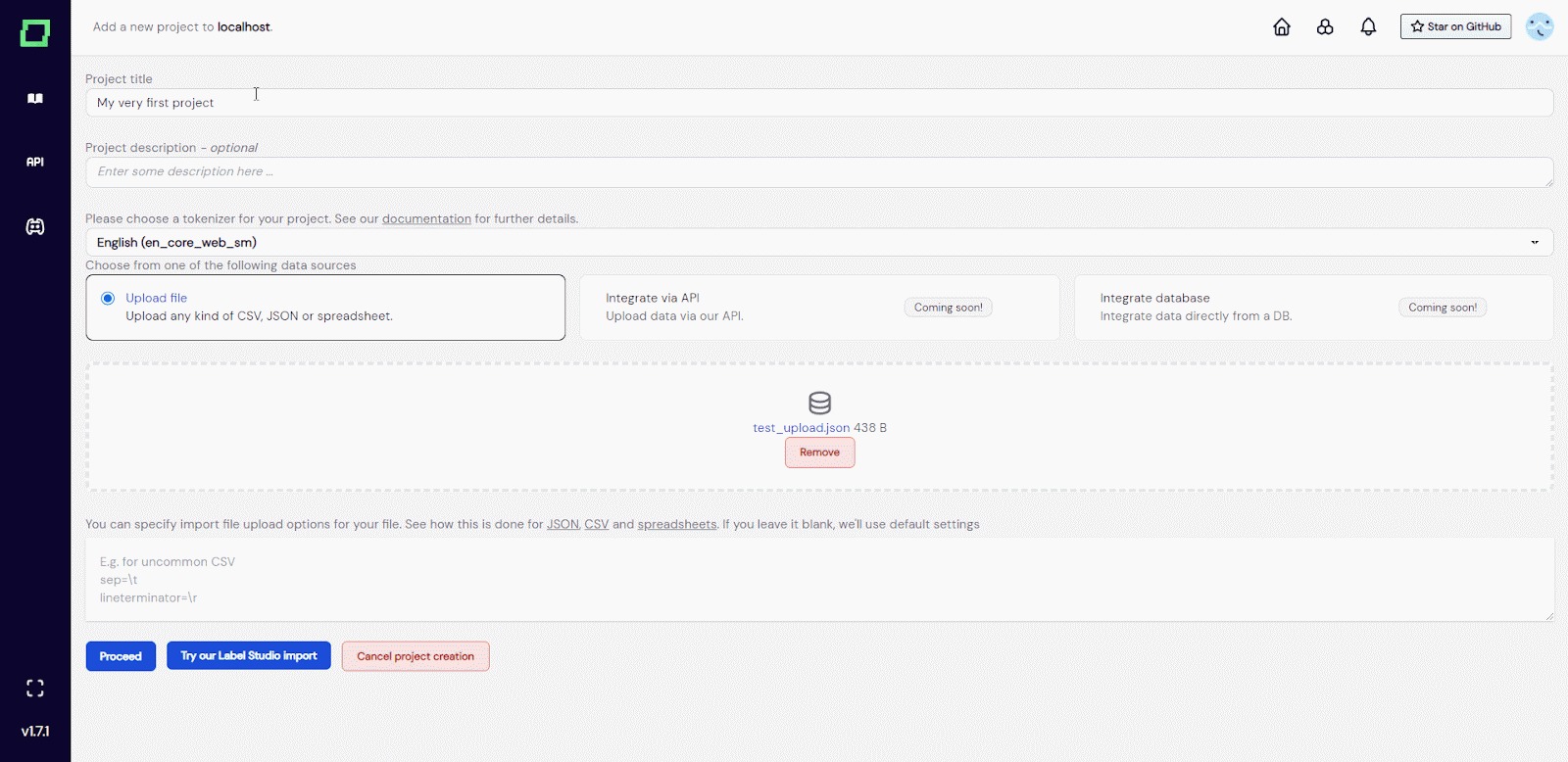
Abb. 3: GIF des Benutzers, der ein Projekt erstellt.
Wie Sie in Abb. 3 sehen können, werden Sie, nachdem Sie alle erforderlichen Informationen eingegeben und Ihre Daten hochgeladen haben, durch Drücken von „Weiter“ zur Einstellungsseite des neu erstellten Projekts weitergeleitet. Der Tokenisierungsprozess wird unter dem Datensatzschema angezeigt, das in diesem Fall sofort abgeschlossen wurde, da unser `test_upload.json` nur aus vier Datensätzen besteht. Stellen Sie sicher, dass Sie den Primärschlüssel Ihrer Daten direkt nach der Projekterstellung auswählen.
[
{
„headline“: „Mike Tyson wird nach einer Niederlage in den Ruhestand gehen“,
„running_id“: 0
},
{
„headline“: „Das irakische Votum bleibt zweifelhaft“,
„running_id“: 1
},
{
„headline“: „Konservative denken über einen Ausweg aus der Wildnis nach“,
„running_id“: 2
},
{
„headline“: „Der Abschlussbericht macht den Ausfall der Instrumente für die Katastrophe von Adam Air-Flug 574 verantwortlich“,
„running_id“: 3
}
]
Wenn Sie sich fragen, was Sie als Nächstes tun sollen, besuchen Sie doch unseren [quickstart] (/refinery/quickstart)? Es führt Sie durch die Anwendung und Sie werden in der Zwischenzeit eine Menge über Raffinerien lernen.
Standardmäßig legt die Open-Source-Version von Refinery einige veränderbare Einschränkungen für die von Ihnen hochgeladenen Daten fest, nämlich die maximale Anzahl von Datensätzen, die maximale Anzahl von Attributen und schließlich die maximale Anzahl von Zeichen für einen Datensatz. Sehen Sie in der Dokumentation der [Konfigurationsseite] (/refinery/configuration-page) nach, ob Ihre Daten diese Anforderungen erfüllen, und passen Sie sie gegebenenfalls an Ihre Bedürfnisse an. Wenn Sie sich innerhalb der festgelegten Grenzen befinden, können wir uns nun die Datenformate ansehen. Sie können CSVs, JSONs oder Excel-Tabellen hochladen. Im Backend wird die hochgeladene Datei mit `Pandas` verarbeitet, sodass Sie Importoptionen für Ihre Dateien genauso angeben können, wie Sie es beim Lesen von [Datenrahmen] tun würden (https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html). Gib sie einfach in das Textfeld unter dem Upload-Feld ein (siehe Abb. 2). Jede Option muss in einer eigenen Zeile stehen und Sie müssen keine Anführungszeichen verwenden, um Zeichenketten zu symbolisieren. Wenn Sie sich nicht sicher sind, welche Parameter Sie angeben können, werfen Sie einen Blick auf die Dokumentationsseiten ([JSON] (https://pandas.pydata.org/docs/reference/api/pandas.read_json.html), [CSV] (https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html), [Spreadsheets] (https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html)). Refinery bietet Unterstützung für die folgenden Datentypen: `category`, `text`, `integer`, `float` und `boolean`. Derzeit gibt es keine Unterstützung für datums- oder zeitbezogene Datentypen. Für die Tokenisierung und Einbettung stehen nur `Text`-Attribute zur Verfügung.
Wenn Sie bereits (teilweise) beschriftete Daten haben, können Sie diese Labels zur hochgeladenen Datei hinzufügen, müssen jedoch einer bestimmten Struktur folgen. Die Raffinerie gruppiert Labels in sogenannten [Labeling-Aufgaben] (/refinery/labeling-tasks), die einen Namen und ein Ziel benötigen. Das Ziel kann entweder ein einzelnes Attribut oder der gesamte Datensatz sein. Um die Labels zu Ihren Daten hinzuzufügen, müssen Sie ein Attribut mit dem folgenden Schema hinzufügen: `$attribute__$name`, wobei die Werte dieses Attributs die Labels selbst sind. Wenn Sie keine Beschriftungen auf Attributebene haben, können Sie das `$attribute` einfach leer lassen, das dann als Bezeichnung für den gesamten Datensatz erkannt wird.
[
{
„headline“: „Mike Tyson wird nach einer Niederlage in den Ruhestand gehen“,
„text“: „Er hat verloren und ist >SIEH DICH, ICH BIN RAUS<, lol“,
„running_id“: 0,
„headline__sentiment“: „neutral“,
„text__style_of_speech“: „informell“
},
{
„headline“: „Das irakische Votum bleibt zweifelhaft“,
„Text“: null,
„running_id“: 1,
„headline__sentiment“: null,
„text__style_of_speech“: null
}
]
<CaptionedImage src="/refinery/project-creation/project_creation_4.png" title="Fig. 4: Screenshot of the settings page after uploading `attribute_labeled_data.json`."/>
[
{
„headline“: „Mike Tyson wird nach einer Niederlage in den Ruhestand gehen“,
„running_id“: 0,
„__sentiment“: „neutrale Stimmung“,
„__relevant“: „nicht relevant“
},
{
„headline“: „Das irakische Votum bleibt zweifelhaft“,
„running_id“: 1,
„__Gefühl“: null,
„__relevant“: „relevant“
}
]
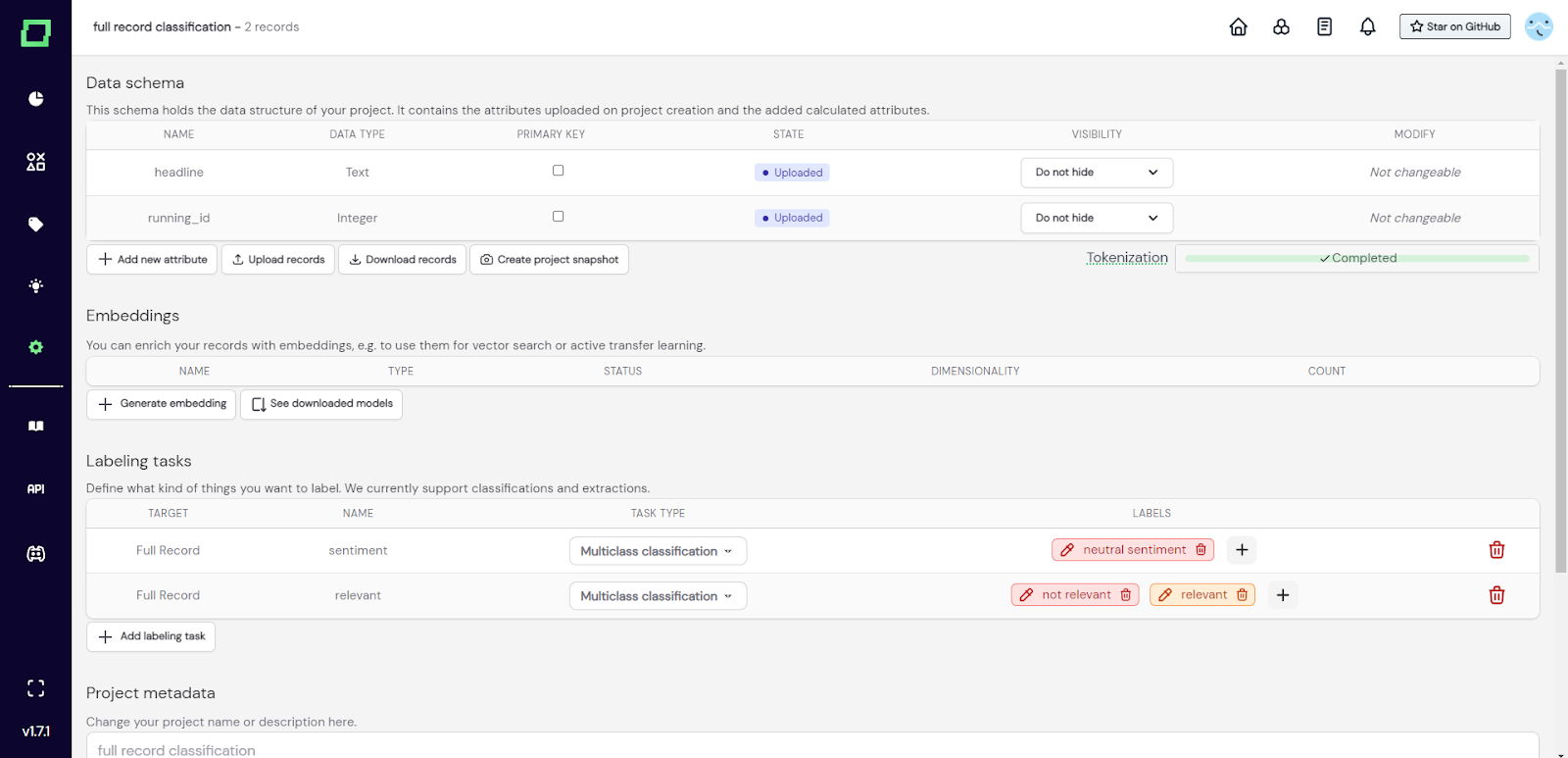
Abb. 5: Screenshot der Einstellungsseite nach dem Upload von `full_record_labeled_data.json`.
Sie können jederzeit weitere Daten in das Projekt hochladen, indem Sie die Einstellungsseite besuchen. Die neuen Daten müssen dieselbe Signatur haben (Menge, Namen und Arten von Attributen) und dürfen nicht gegen die Primärschlüsselbeschränkungen verstoßen, die für Ihre Daten festgelegt werden müssen. Wenn Sie noch keinen Primärschlüssel festgelegt haben, sollten Sie dies tun, da nur so Duplikate vermieden werden können!
[
{
„headline“: „Was sollten Sie zum White Elephant Gift Exchange in Ihrem Büro mitbringen“,
„running_id“: 5,
„__sentiment“: „neutrale Stimmung“,
„__relevant“: „nicht relevant“,
„__clickbait“: „Clickbait“
},
{
„headline“: „Kim stellt einen Eislaufrekord auf und gewinnt ihren ersten Weltmeistertitel“,
„running_id“: 4,
„__sentiment“: „neutrale Stimmung“,
„__relevant“: „relevant“,
„__clickbait“: „kein Clickbait“
}
]
Sie können jedoch neue Labeling-Aufgaben und Labels hinzufügen, indem Sie neue Daten hochladen, was in Abb. 6 dargestellt ist, wo das Projekt von Abb. 5 um die neuen `more_data.json`-Daten erweitert wird.
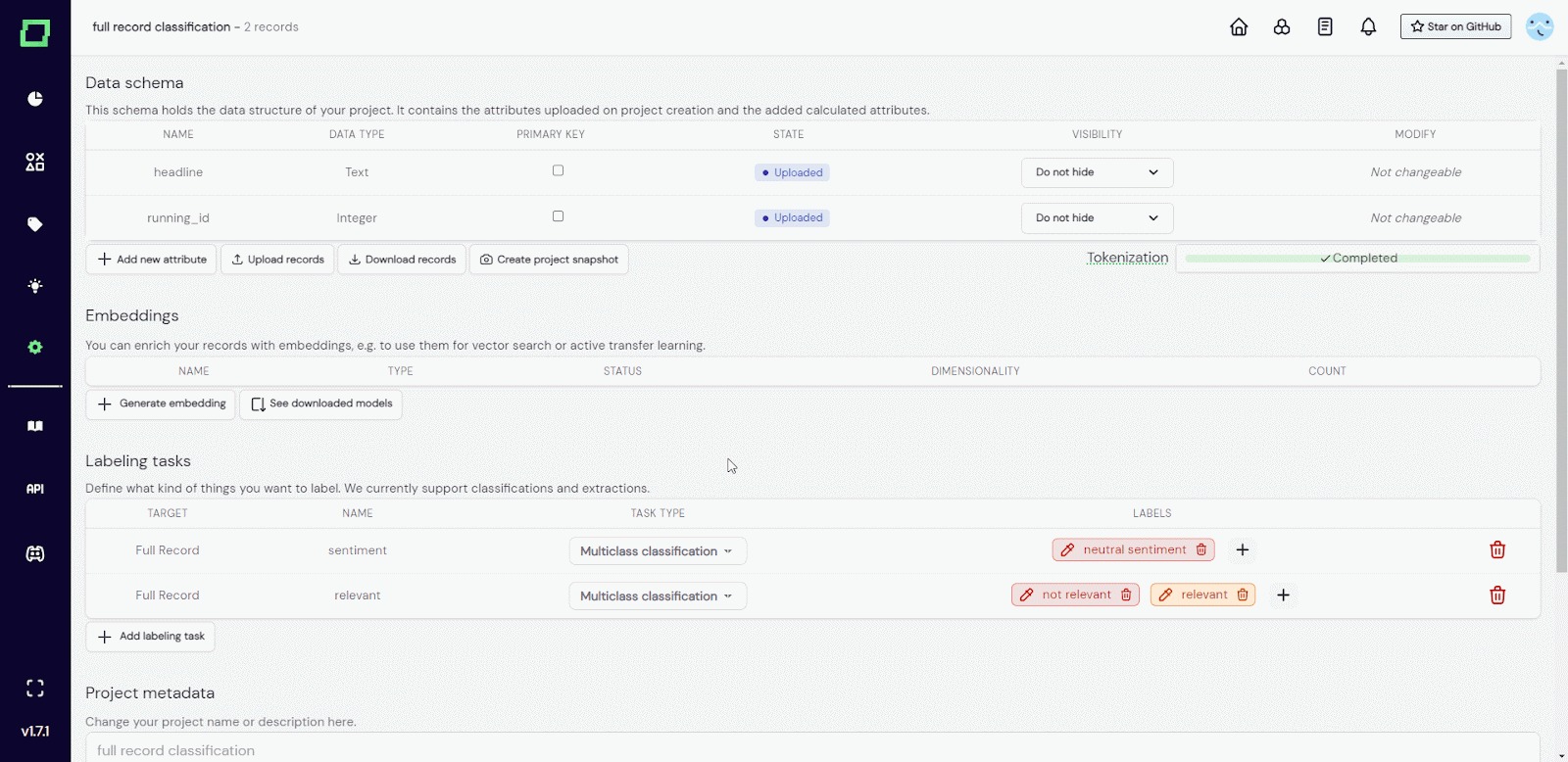
Abb. 6: GIF des Benutzers, der `more_data.json` zum Projekt aus Abb. 5 hinzufügt. Beachten Sie, wie der Benutzer zuerst sicherstellt, dass er den Primärschlüssel festlegt. Vor dem Upload hatte das Projekt zwei Kennzeichnungsaufgaben. Beim Upload wurde die neue Etikettierungsaufgabe `Clickbait` hinzugefügt.
Ein laufendes ID-Attribut in der Raffinerie ist von großem Wert, da Sie damit Ihre Daten mit einfachen Ganzzahlen filtern können. Wenn die Raffinerie feststellt, dass Ihre Daten kein Integer-Attribut enthalten, erstellt die Raffinerie automatisch ein `running_id`-Attribut. Falls Sie dieses Attribut nicht sehen möchten, können Sie es jederzeit mithilfe der Einstellungen für [Attributsichtbarkeit] (/refinery/attribute-visibility) ausblenden.