
Sie können die Raffinerie verwenden, um Ihre Daten zu analysieren und zu überwachen.
Die Übersichtsseite (manchmal auch als „Überwachungsseite“ bezeichnet) wurde entwickelt, um den Überblick darüber zu behalten, was in Ihrem Projekt passiert. Sie können den Fortschritt der Kennzeichnung, den Umfang der Heuristiken, die Labelverteilung und vieles mehr überprüfen. Das Beste daran: Sie können all diese Statistiken und Grafiken auf vordefinierten Abschnitten Ihrer Daten und für einzelne Beschriftungsaufgaben anzeigen.
Bevor Sie sich Statistiken und Diagramme zu Ihrem Projekt ansehen, stellen Sie immer sicher, dass Sie oben auf der Seite das richtige Ziel, die richtige Beschriftungsaufgabe und den richtigen Datenbereich auswählen. Der einfachste Weg, sich einen Überblick über den Stand des Projekts zu verschaffen, besteht darin, sich die aggregierten Statistiken oben auf der Seite anzusehen. Hier sehen Sie die Menge der manuell beschrifteten Daten, der schwach überwachten Daten, der Heuristiken und schließlich (wenn Sie die [verwaltete Version] (/refinery/managed-version) verwenden) die Vereinbarung zwischen den Annotatoren. Sie können mit der Maus über all diese Elemente fahren, um weitere Informationen zu erhalten. In den folgenden Unterabschnitten werden die verfügbaren Visualisierungen behandelt.
Dieses gruppierte Balkendiagramm (siehe Abb. 1) zeigt Ihnen die Verteilung der angegebenen Labels, gruppiert nach den Labelnamen. Die verschiedenen Farben geben an, ob das Etikett manuell oder unter schwacher Aufsicht angebracht wurde. Wenn Sie mit der Maus über die Balken fahren, erhalten Sie weitere Informationen. Dieses Diagramm ist sehr nützlich, um unter- oder überrepräsentierte Klassen zu erkennen, was darauf hindeuten könnte, dass zwei Labels aufgeteilt oder zusammengeführt werden müssen, um einen relativ ausgewogenen Trainingsdatensatz zu erhalten. Außerdem sollte die Verteilung der manuell beschrifteten und schwach beaufsichtigten Daten ungefähr übereinstimmen, da du andernfalls Klassen aufgrund der starken Skalierung schwach beaufsichtigter Gruppen über- oder unterrepräsentierst. Wenn sie nicht in etwa übereinstimmen, sollten Sie erwägen, den Klassen, die Schwierigkeiten haben, Schritt zu halten, weitere Heuristiken hinzuzufügen und die Heuristiken der überrepräsentierten Klasse vorübergehend zu entfernen.
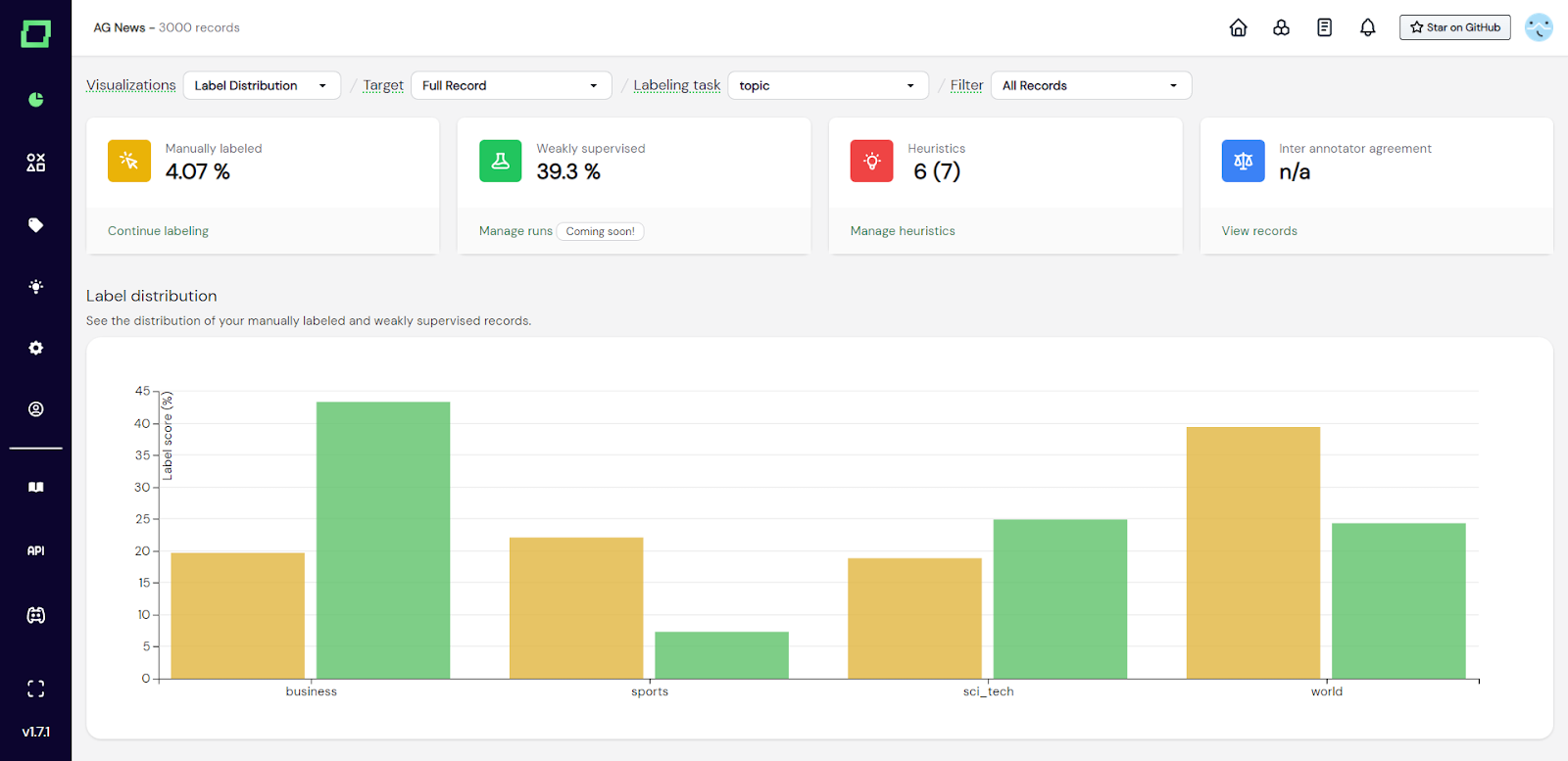
Abb. 1: Screenshot der Monitoring-Seite, die das Label-Verteilungsdiagramm zeigt.
Das Diagramm der Konfidenzverteilung zeigt die Perzentile schwach überwachter Daten im Vergleich zum schwachen Konfidenzwert der Aufsicht. Es ist wichtig, dieses Diagramm in Kombination mit der Gesamtzahl der Kennzahlen zu untersuchen, die für eine schwache Aufsicht kennzeichnend sind, da Sie in der Regel am meisten an den Daten interessiert sind, für die ein hohes Konfidenzniveau angegeben wurde. Das Diagramm ist wie folgt zu lesen: In Abb. 2 sehen Sie, dass das 40. Perzentil einem Konfidenzwert von ~ 90% gegenübergestellt ist. Das bedeutet, dass 40% Ihrer schwach überwachten Daten ungefähr zwischen 0 und 90% Konfidenz liegen.
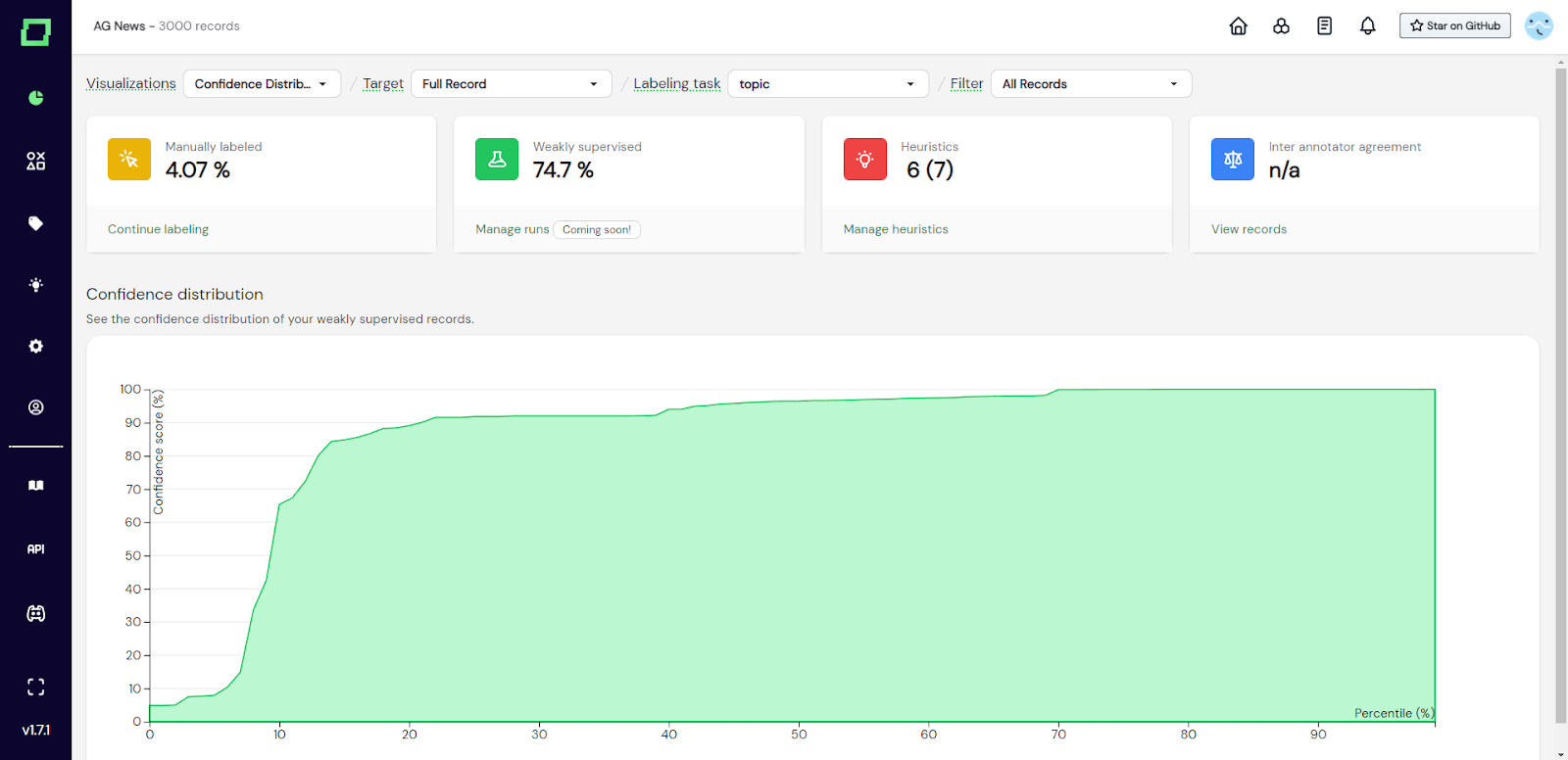
Abb. 2: Screenshot der Monitoring-Seite, die das Diagramm der Konfidenzverteilung zeigt.
Die Konfusionsmatrix ist Ihre wichtigste Visualisierung, um eine schwache Aufsichtsqualität zu verstehen. Sie stellt die schwach überwachten Labels den manuellen Referenzkennzeichnungen gegenüber, sodass Sie auf einen Blick erkennen können, wo eine schwache Überwachung erfolgreich ist und wo nicht. In Kombination mit der Filterung durch den Datenbrowser ist dies besonders effektiv, da Sie dann einfach die Bezeichnungen auswählen können, bei denen die größte Unstimmigkeit besteht, und manuell überprüfen können, ob es sich tatsächlich um Fehler einer schwachen Überwachung oder um Kennzeichnungsfehler handelt. Verwenden Sie dieses Diagramm, um Ihre Heuristiken und schwache Überwachung iterativ zu verfeinern.
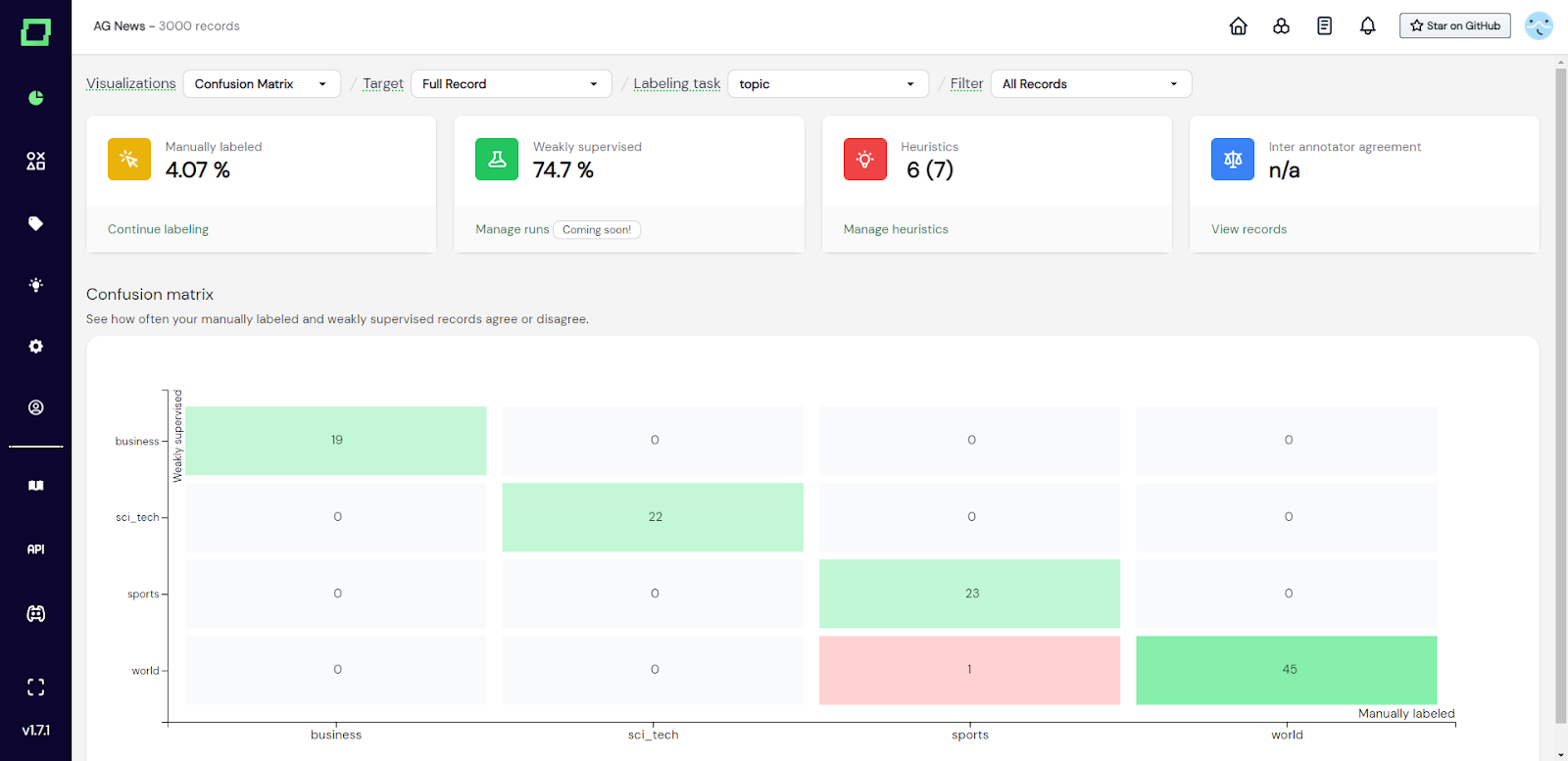
Abb. 3: Screenshot der Überwachungsseite, die die Konfusionsmatrix zeigt.
Wenn Sie die verwaltete Version von Refinery verwenden, erhalten Sie automatisch Support für mehrere Benutzer. Da es mittlerweile potenziell viele verschiedene Etikettierer gibt, kann es auch bei deren Etikettierung unterschiedliche Meinungen geben. Mit der Vereinbarung zwischen den Annotatoren können Sie auf einen Blick sehen, wie viele Benutzer zustimmen oder nicht. Das kann Ihnen helfen, Leute zusammenzubringen, die ein anderes Verständnis von der jeweiligen Etikettierungsaufgabe zu haben scheinen. In Abb. 4 zum Beispiel sollte der Benutzer mit dem roten Avatar wirklich mit den anderen Etikettierern sprechen.
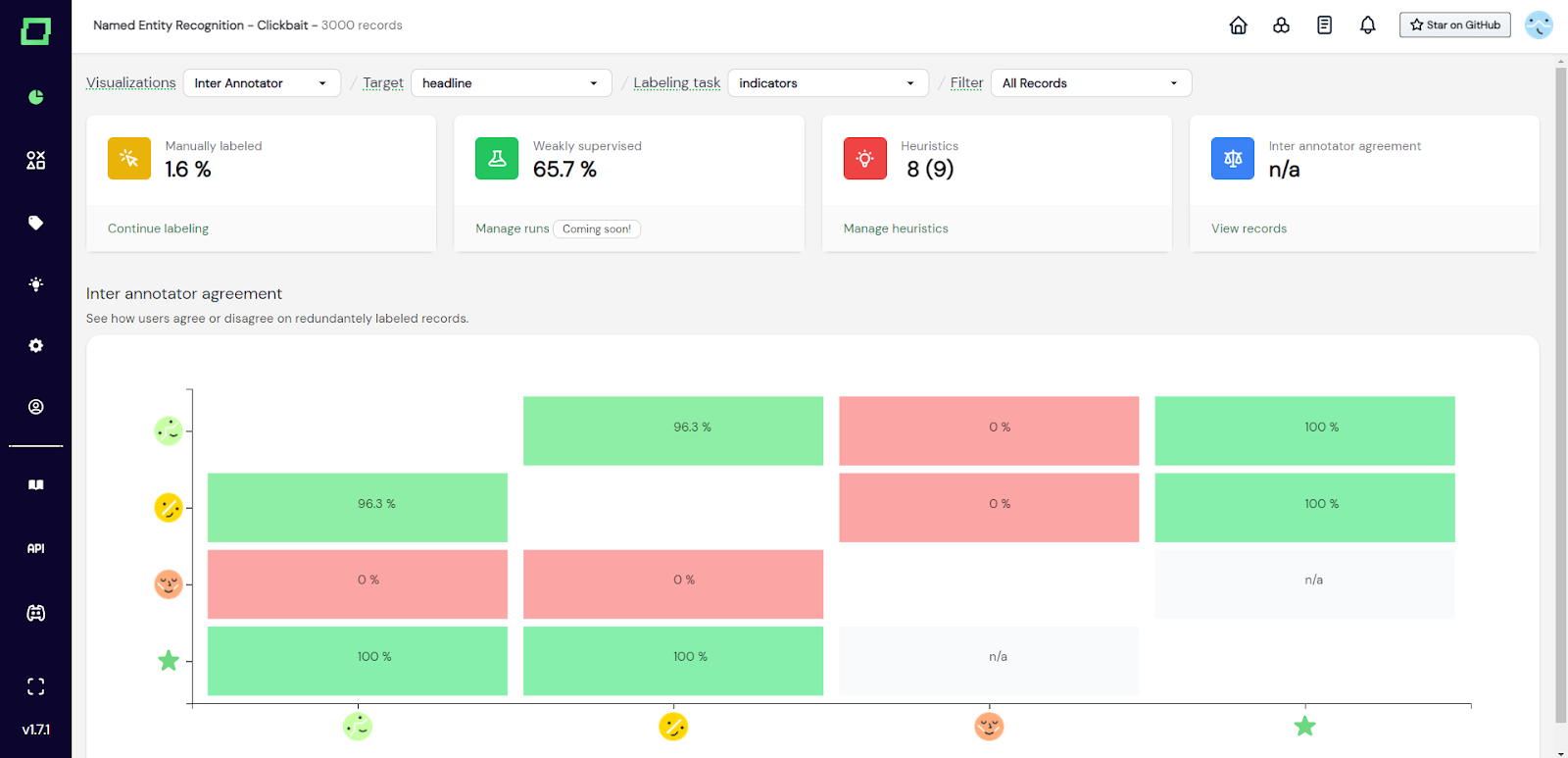
Abb. 4: Screenshot der Monitoring-Seite, die das Diagramm der Vereinbarung zwischen den Annotatoren zeigt.
Sie können den Datensatz, der analysiert wird, auch auf der Übersichtsseite reduzieren, indem Sie in der Dropdownliste oben rechts einen **statischen** Datenbereich auswählen. Auf diese Weise werden alle Grafiken und Statistiken gefiltert, sodass Sie tiefere Einblicke in Ihre potenziellen Schwachstellen erhalten.
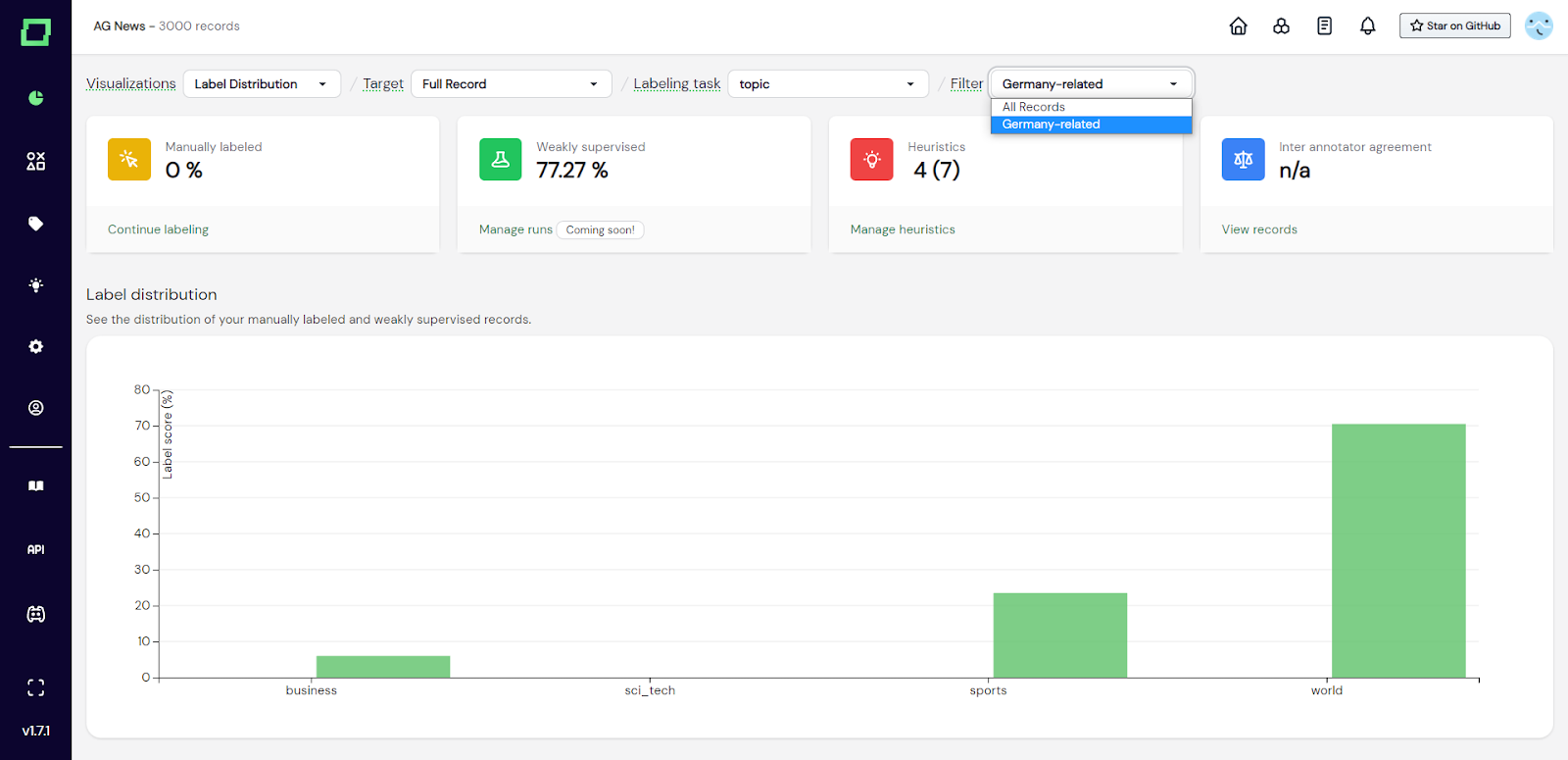
Abb. 5: Screenshot der Monitoring-Seite, auf der der Benutzer die Statistiken und Visualisierungen gefiltert hat, um nur den statischen Datenbereich mit dem Namen „Deutschlandbezogen“ zu berücksichtigen.
Um mehr über Data Slices zu erfahren, lesen Sie die Seite über [Datenmanagement] (/refinery/data-management #saving -filters).