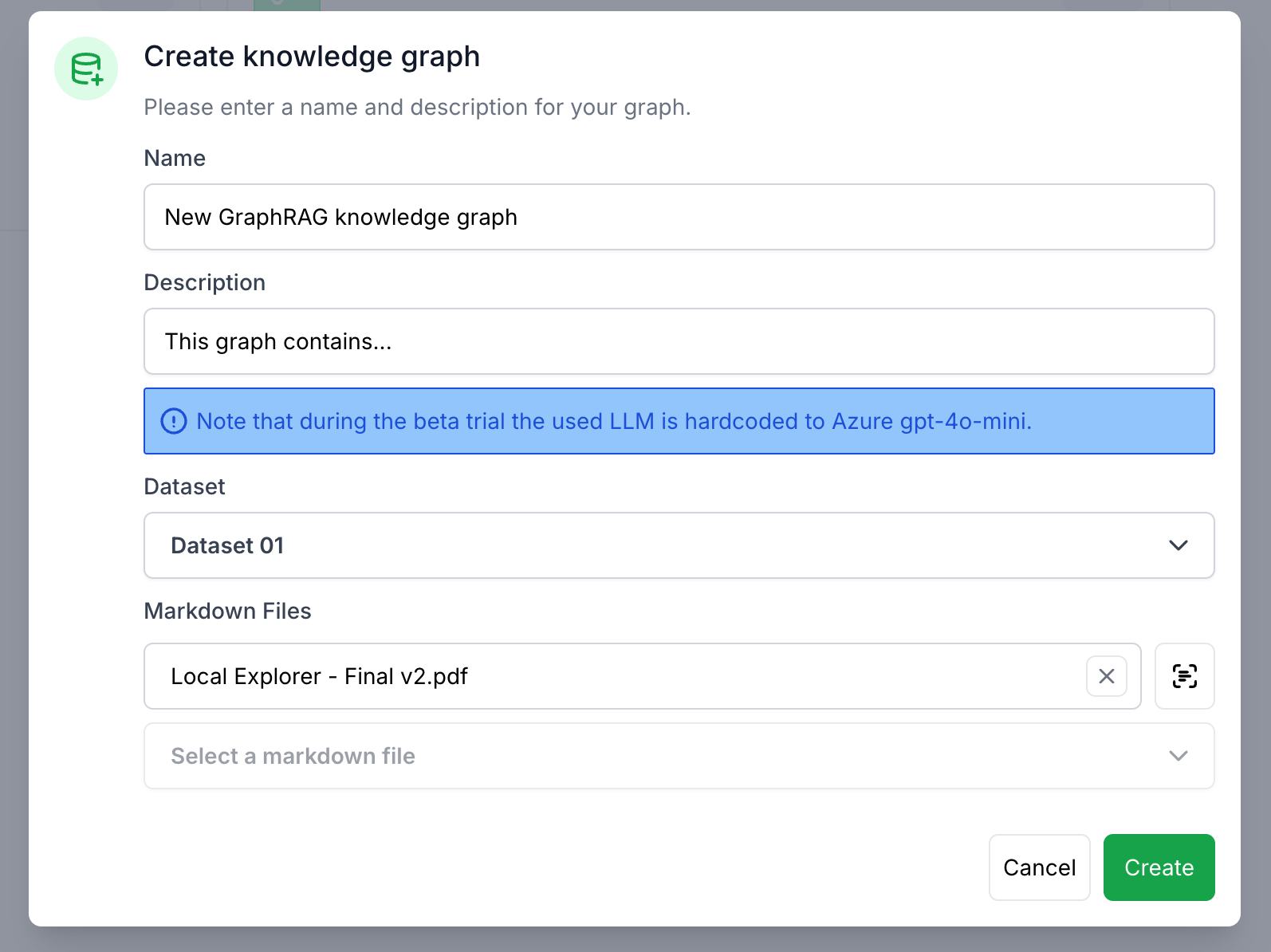
Bei Cognition gibt es eine Datenverarbeitungspipeline, die als ETL (Extract, Transform, Load) bekannt ist. Diese Pipeline übernimmt die Verarbeitung von Daten in Form von PDF-Dateien.
Cognition bietet eine ETL-Datenverarbeitungspipeline (Extract, Transform, Load) für die Arbeit mit PDF-Dateien. Es konvertiert den Inhalt in das Markdown-Format und teilt ihn in kleinere Teile auf, um es einem großen Sprachmodell (LLM) zu erleichtern, die Informationen zu analysieren und zu verwenden. Dieser Prozess des Chunkings ist ein integraler Bestandteil jeder Retrieval-Augmented Generation (RAG) -Pipeline, der dem System hilft, relevante Informationen effektiv abzurufen und zu generieren.
Die Extraktion ist der erste Schritt in der ETL-Pipeline und bezieht sich auf die Extraktion des Textinhalts aus dem PDF. Sie kann mit einem Vision-Based Large Language Model (LLM) oder mit auswählbaren Tools wie pdf2markdown und Azure Document Intelligence (Azure DI) durchgeführt werden. Für kürzere PDFs ohne komplexe Layouts wie Tabellen oder mehrspaltige Formate ist pdf2markdown eine geeignete Option. Beachten Sie, dass es nur mit PDFs funktioniert, die auswählbaren Text enthalten und geschützte Dateien nicht verarbeiten können. Für komplexere Dokumente oder solche ohne auswählbaren Text werden Azure DI und die Vision LLMs empfohlen.
Der Transformationsschritt der ETL-Pipeline wird von einem LLM abgewickelt, der für die Reinigung, Strukturierung und Verfeinerung der extrahierten Daten verantwortlich ist. Dieses LLM kann ein Modell sein, das auf Plattformen wie Azure, Azure Foundry oder OpenAI gehostet wird. Während des Transformationsprozesses führt das LLM Aufgaben wie das Entfernen unnötiger Formatierungen, die Standardisierung der Struktur und das Konvertieren komplexer Elemente wie Tabellen in ein besser verwendbares Format aus.
Um mit der Verarbeitung zu beginnen, erstellen Sie zunächst einen Datensatz, in den Sie Ihre Dateien hochladen können. Auf der linken Seite der Cognition-Startseite befindet sich eine Seitenleiste. Klicken Sie auf „ETL“ und dann auf „Neuen Datensatz erstellen“. Um nach einem vorhandenen Datensatz zu suchen, klicken Sie auf „Datensätze anzeigen“. Als Teil der Tabelle kann der Techniker die Konfiguration des Datensatzes sehen.
Sie können den Datensatz benennen und beschreiben, wie Sie möchten. Wählen Sie die Sprache aus. Derzeit sind die verfügbaren Sprachen Deutsch und Englisch. Das englische System ist so konfiguriert, dass es auch andere Sprachen unterstützt.
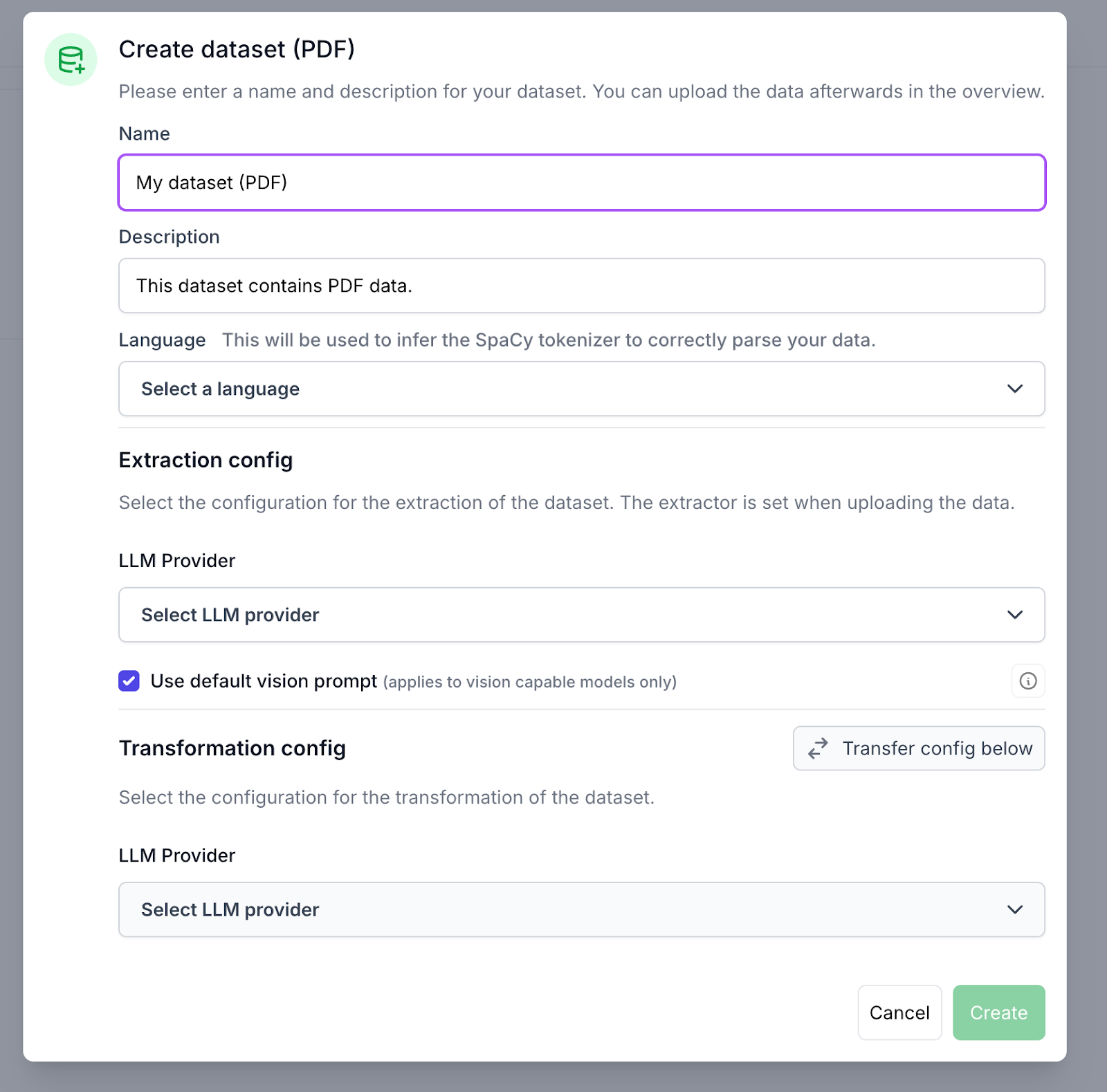
Wählen Sie Azure (Azure Foundry ebenfalls verfügbar, aber nur für die Transformation) oder OpenAI als LLM-Anbieter und füllen Sie die Felder API-Schlüssel, Engine usw. mit Ihren Anmeldeinformationen aus. Sie können dieselben Anmeldeinformationen sowohl für die Extraktions- als auch für die Transformationskonfiguration verwenden. Je nach LLM-Anbieter sind unterschiedliche Felder erforderlich (entweder für die Extraktion oder Transformation), wie zum Beispiel:
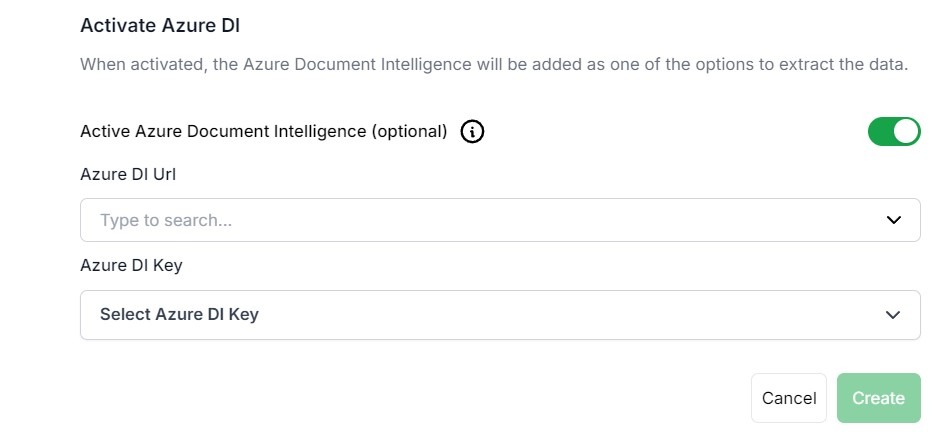
Wenn Sie Azure DI als Extraktionsmethode verwenden möchten, aktivieren Sie es mit den entsprechenden Anmeldeinformationen. Die Azure-DI benötigt einen API-Schlüssel und eine Azure-DI-URL.
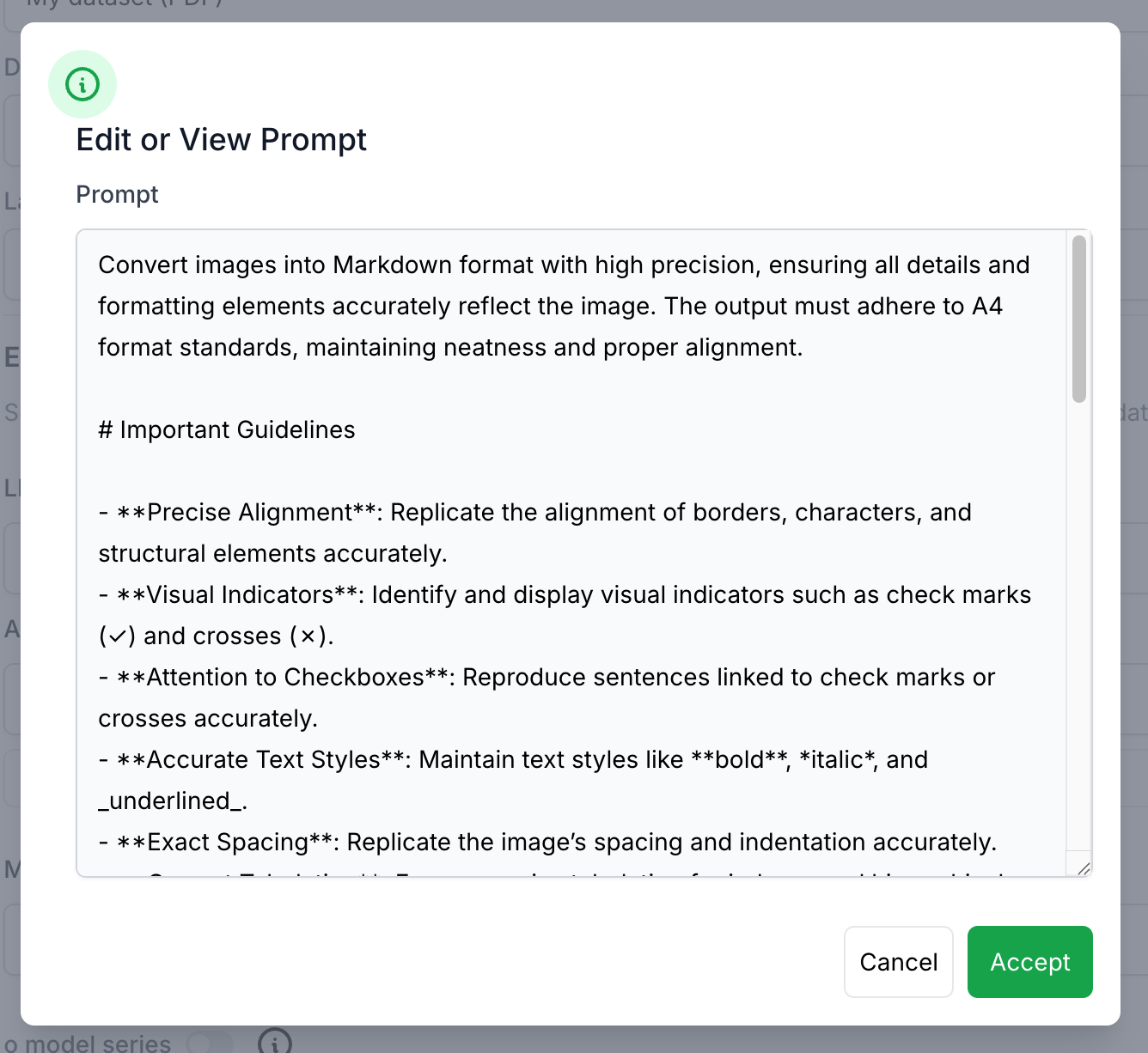
Beim Erstellen eines neuen Datensatzes kann die Eingabeaufforderung entweder konfiguriert oder die Standardeingabe verwendet werden. Wenn Sie auf die Schaltfläche mit dem Infokreis klicken, wird ein Fenster zum Anpassen der Vision-Eingabeaufforderung geöffnet. Die Bildaufforderung galt nur für sehfähige Modelle. Hinweis: Ohne die Sprache und den Extraktor auszuwählen, wird die Schaltfläche deaktiviert.
Beispiel für die englische Sprache:
Eine weitere Konfiguration beim Erstellen eines Datensatzes ist die Option, die Modellreihe o zu aktivieren. (z. B. o1 & o3).
Wenn Sie alles konfiguriert haben, klicken Sie auf „Erstellen“. Sie können jetzt Dateien von Ihrem Gerät hochladen.
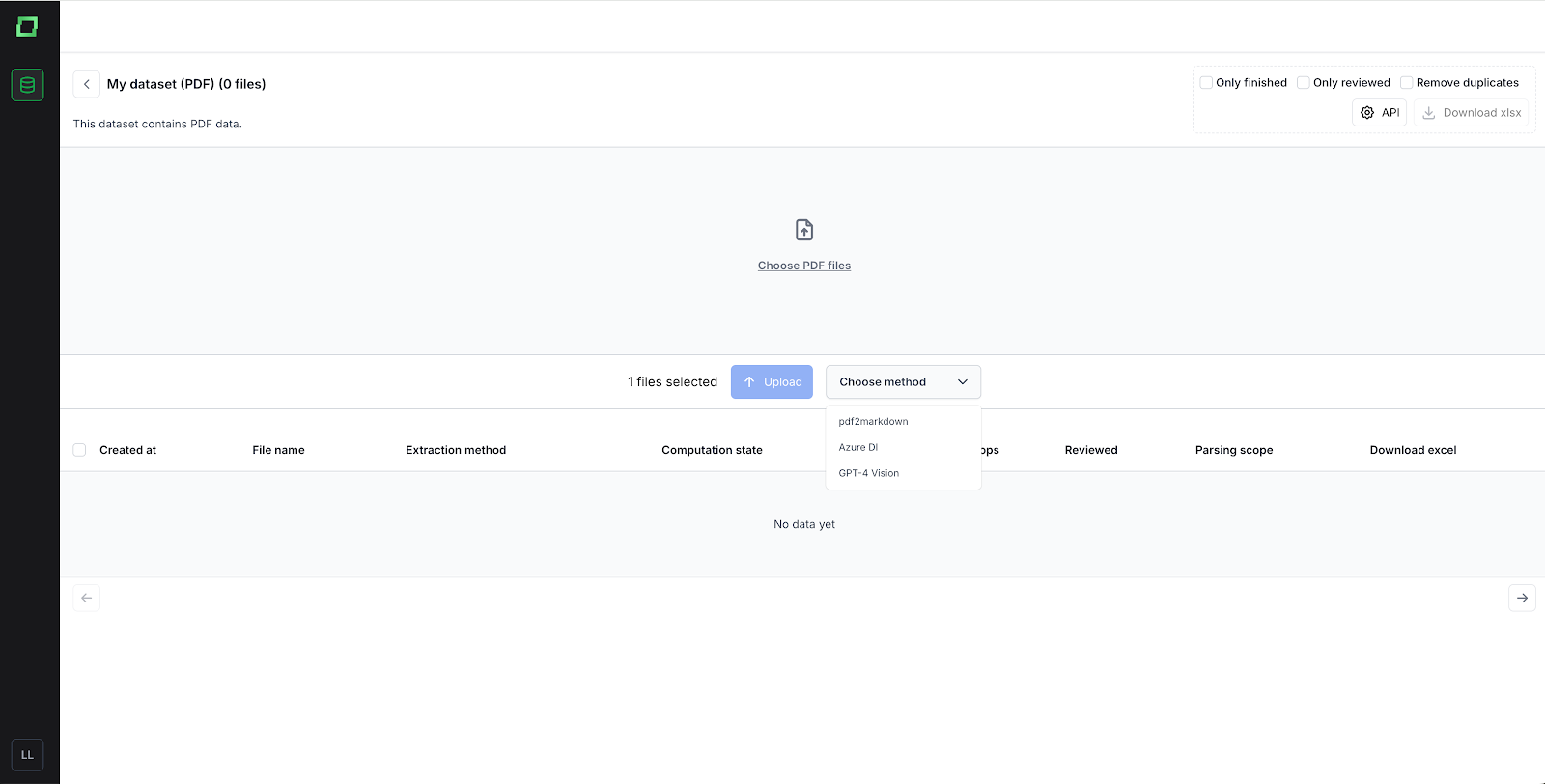
Wählen Sie beim Hochladen von Dokumenten die Extraktionsmethode. Die verfügbaren Methoden sind pdf2markdown, Azure DI und GPT-4 Vision. Sie können für jeden Upload eine dieser Methoden auswählen (sofern für Azure DI konfiguriert). Bei jedem Upload können Sie eine oder mehrere Dateien einreichen. Sie können auch verschiedene Methoden innerhalb desselben Datensatzes verwenden.
Falls die Datei in der Pipeline fehlschlägt, versuchen Sie, sie zu löschen und eigenständig hochzuladen. Das Problem könnte sein, dass die Datei zu lang ist. Wenn die Datei länger als 100 Seiten ist, empfiehlt es sich, sie in kürzere Dateien aufzuteilen.
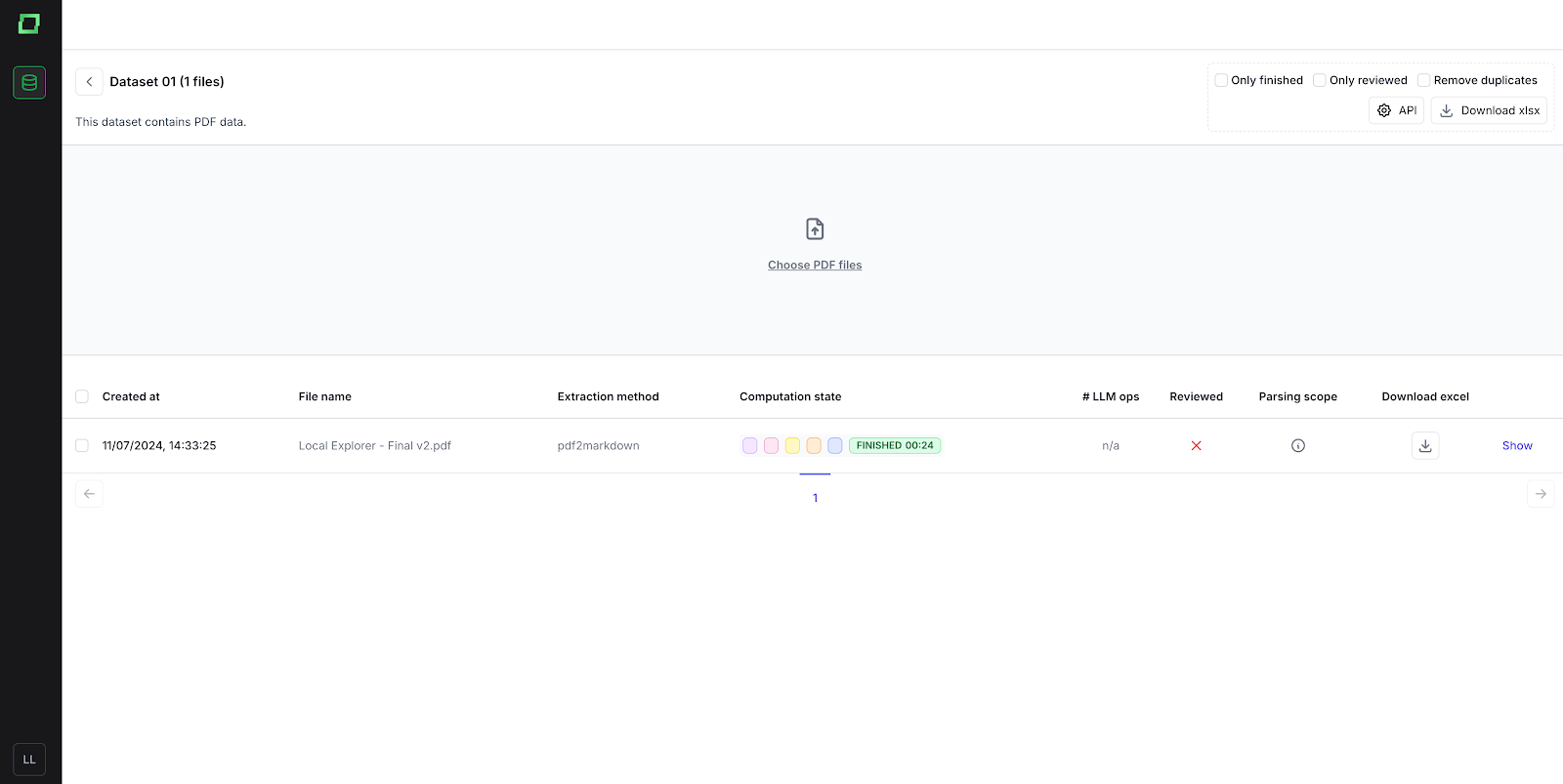
Wenn die Datenextraktion abgeschlossen ist, wird im Berechnungsstatus „abgeschlossen“ angezeigt. Wenn die Datei hochgeladen wird, durchläuft sie mehrere Stufen. Weitere Informationen zum Hochladen von Daten finden Sie im folgenden Abschnitt: Abschnitt „Daten hochladen“.
Sie können auf „Anzeigen“ klicken, um die bearbeitete Datei zu öffnen. Der Inhalt ist jetzt in Blöcke aufgeteilt. Auf der linken Seite können Sie das Dokument bearbeiten. Auf der rechten Seite wird eine Vorschau der Bearbeitung angezeigt. Die Bearbeitung erfolgt mit Markdown.
Abschlag ist eine Methode zum Schreiben von Text, mit der Sie einfache Formatierungen wie Fett, Kursivschrift, Listen und Überschriften hinzufügen können. Es verwendet leicht zugängliche Satzzeichen über die Tastatur, sodass Sie formatierte Dokumente erstellen können, ohne komplizierte Software zu benötigen.
Markdown ist einfach und übersichtlich, was es LLMs erleichtert, den Text zu lesen und zu verstehen. Da es einfach ist, können sich LLMs auf den Inhalt und die Bedeutung des Textes konzentrieren, ohne durch komplizierte Formatierungen verwirrt zu werden.
Die Blöcke sind durch drei Striche (---) getrennt. Während andere Markdown-Symbole optional sind, sind die Bindestriche als Trennzeichen für Abschnitte obligatorisch.
Um eine Zeile in eine Überschrift umzuwandeln, schreiben Sie # gefolgt von einem Leerzeichen. In Markdown gibt es sechs Größen von Überschriften, und die Größe der Überschriften verringert sich mit jedem weiteren #, das Sie hinzufügen. Das bedeutet, dass die kleinste Überschrift mit ###### geschrieben wird.
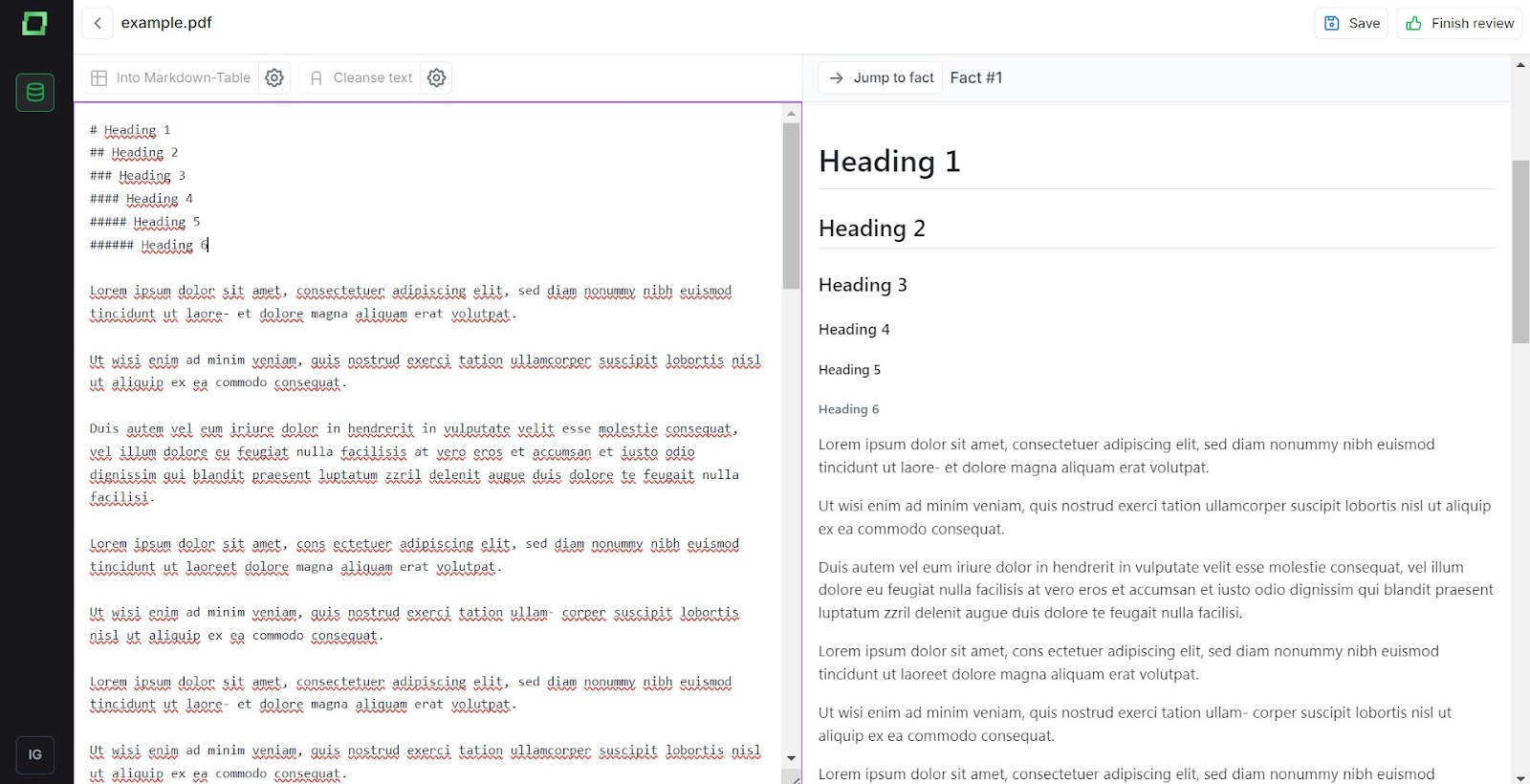
Um eine Liste zu erstellen, schreiben Sie - gefolgt von einem Leerzeichen. Um Unterelemente hinzuzufügen, verwenden Sie doppelte Bindestriche mit einem Leerzeichen dazwischen, wie folgt: - -. Um ein Wort fett zu machen, schreiben Sie es zwischen zweien**. Um ein Wort kursiv zu schreiben, verwenden Sie nur ein*. Um eine leere Zeile zu erstellen, drücken Sie zweimal die EINGABETASTE.

Bevor wir auf die Details der Bearbeitung eingehen, hier ist ein schnelle Checkliste:
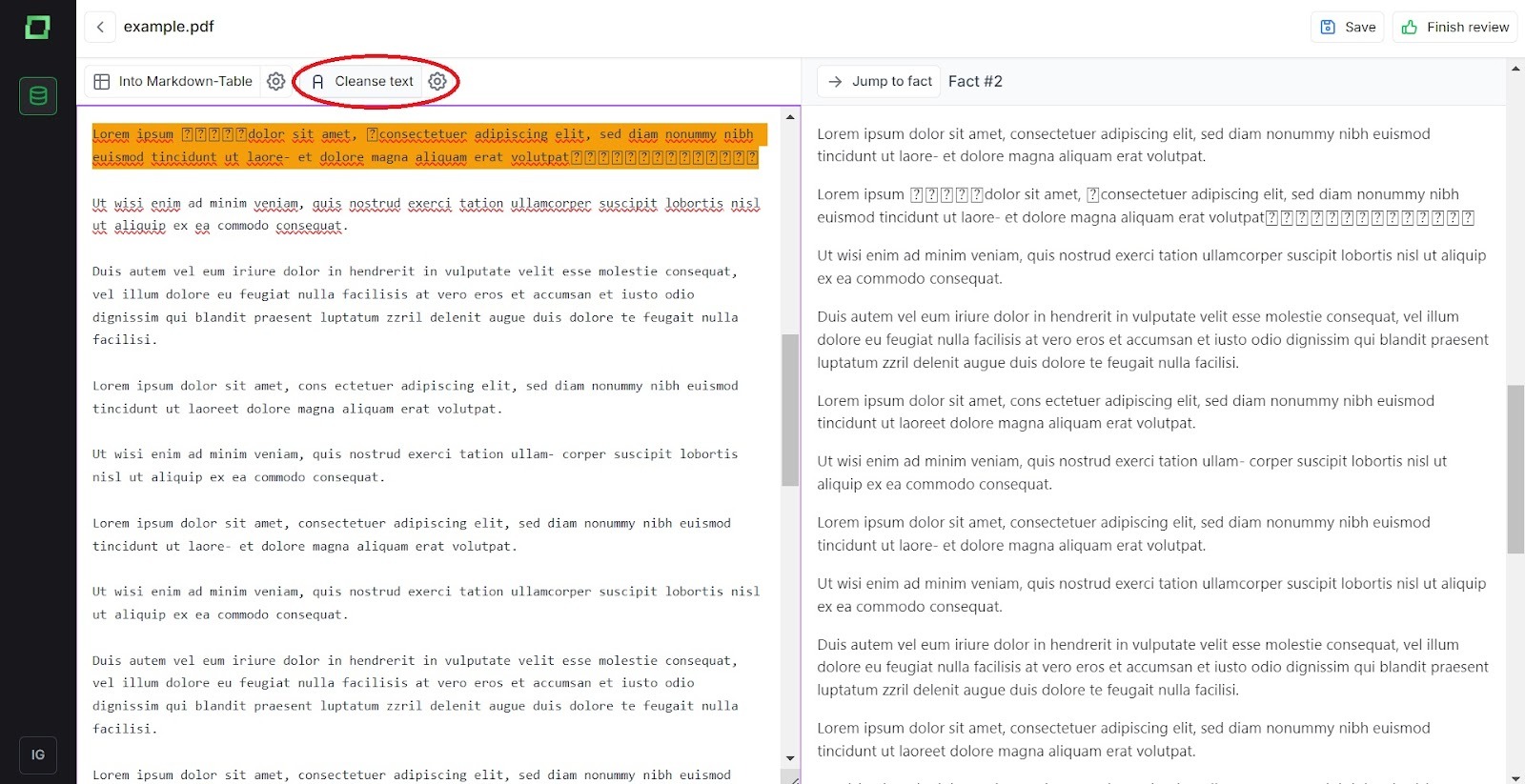
In einem verarbeiteten Dokument müssen Sie zunächst überprüfen, ob unerwünschte Sonderzeichen vorhanden sind. Einige Bilder oder Symbole werden möglicherweise falsch verarbeitet und verursachen unerwünschte Zeichen, wie z. B. „“. Diese sollten gelöscht werden, da sie es einem LLM erschweren, den Text zu interpretieren, und außerdem zusätzliche Zeichen verbrauchen, was die Kosten erhöht. Sie können die Option „Text reinigen“ oben links auf der Seite verwenden. Um diese Funktion nutzen zu können, müssen Sie zuerst den Zielbereich auswählen.
Eine weitere wichtige Überprüfung besteht darin, sicherzustellen, dass keine Informationen verloren gehen. Um dies schnell zu erledigen, überprüfen Sie den Anfang und das Ende jeder Seite. Wenn diese Abschnitte korrekt aussehen, ist der Rest der Seite normalerweise in Ordnung. Überprüfen Sie außerdem alle Textfelder, die in einer kleinen Schrift an den Seiten der Seite geschrieben sind.
Wenn Sie vermuten, dass dabei mehrere Textteile verloren gegangen sind, überdenken Sie Ihre Extraktionsmethode. Verwenden Sie die andere Methode, die für das Dokument besser geeignet ist. In der Regel ist es besser, zu Azure DI zu wechseln.
Tabellen sollten ebenfalls überprüft werden. Es ist zwar nicht unbedingt erforderlich, dass Tabellen exakt wie das Original aussehen, aber der Inhalt sollte klar sein und die Zeilen sollten korrekt verarbeitet werden. Die Informationen werden auch in Form von einfachen Linien nützlich sein. Wenn Sie Tabellen bevorzugen, können Sie einfache Linien in Markdown-Tabellen umwandeln. Wählen Sie die Zeilen aus, die Sie konvertieren möchten, und klicken Sie oben links auf der Seite auf „In Markdown-Table“.
Überprüfen Sie abschließend das Chunking. Idealerweise sollten Abschnitte einzelnen Abschnitten des Dokuments entsprechen (d. h. dem Text unter Überschriften oder Unterüberschriften). Je nach Abschnittsgröße kann ein Abschnitt durch mehrere Abschnitte dargestellt werden. Der Einfachheit halber kann jeder Absatz einen einzelnen Abschnitt bilden. Der erste Teil jedes Abschnitts sollte natürlich die Überschrift und/oder Unterüberschrift enthalten. Überschriften oder Unterüberschriften sollten nach Möglichkeit auch in anderen Abschnitten enthalten sein.
Darüber hinaus sollten Tabellen, Aufzählungspunkte und Listen jeweils ihren eigenen Abschnitt haben. Wenn ein Absatz, eine Tabelle, eine Liste usw. zu lang ist, können sie erneut in mehrere Abschnitte aufgeteilt werden, die wiederum die Überschrift oder Unterüberschrift enthalten.
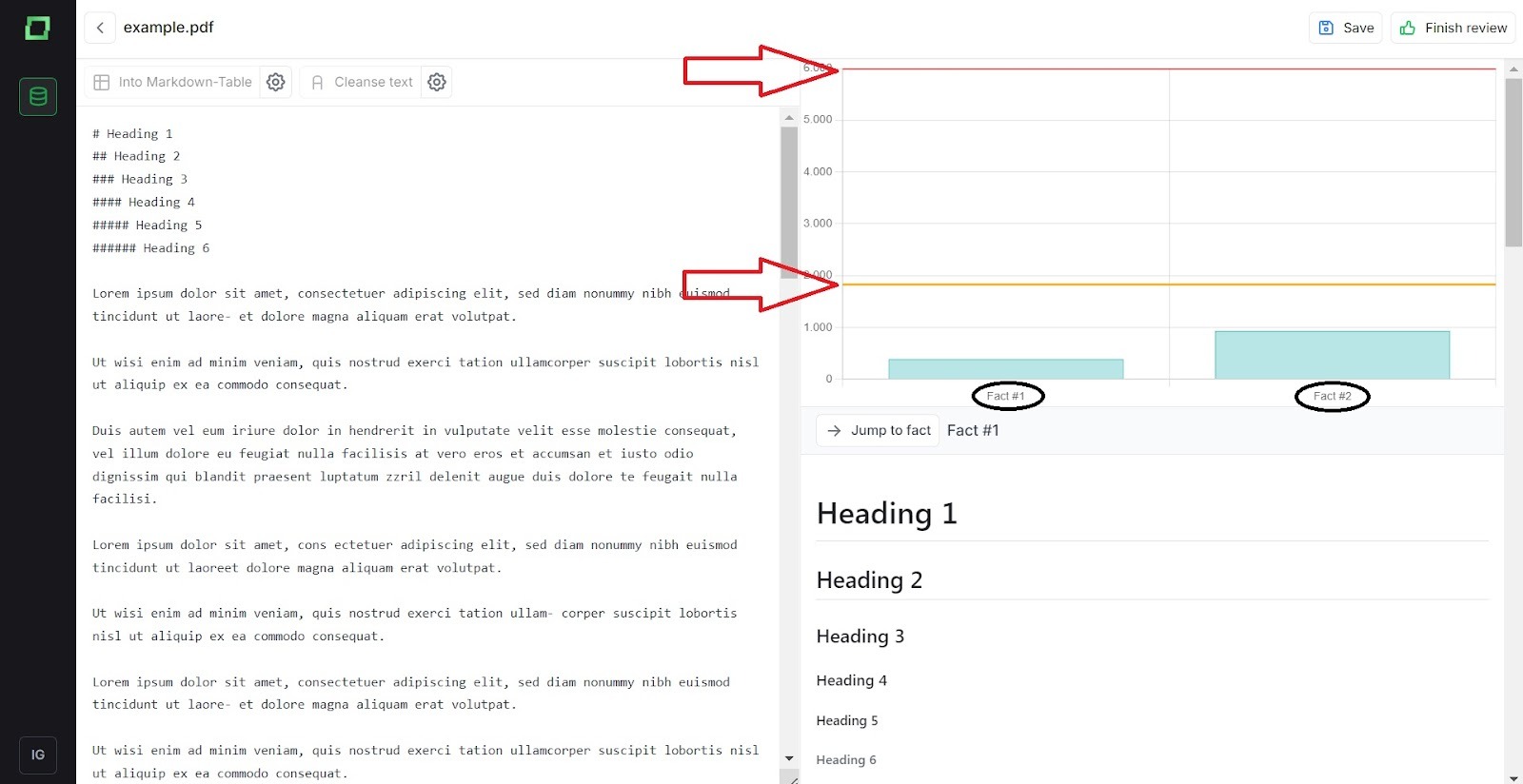
Wie entscheiden wir, ob ein Stück zu lang ist? Wenn Sie vollständig nach oben gescrollt sind, sehen Sie auf der rechten Seite ein Balkendiagramm, in dem „Fakten“ verglichen werden. Fakten sind nummerierte Teile. Der erste Teil ist Fakt #1 und so weiter. Wenn ein Fakt unter der gelben Linie liegt, ist seine Länge optimal. Wenn ein Fakt unter der roten Linie liegt, ist die Länge immer noch akzeptabel, sollte aber nach Möglichkeit gekürzt werden. Jeder Abschnitt oberhalb der roten Linie muss gekürzt werden, damit er mindestens unter die rote Linie oder idealerweise unter die gelbe Linie fällt.
Ein Block kann nicht leer sein. Ein sehr kurzer Block, der beispielsweise nur einen Satz enthält, ist zulässig. Abschnitte, die ausschließlich aus Satzzeichen oder Sonderzeichen bestehen, sind ungültig. Sie müssen mindestens einen Buchstaben enthalten.
Wenn das Dokument lang ist und Sie keine Zeit für die manuelle Bearbeitung haben, sollten Sie der Überprüfung der Aufteilungsregeln und dem Entfernen unerwünschter Sonderzeichen Priorität einräumen.
Um direkt zu einem Block zu springen, können Sie auf den entsprechenden Fakt klicken. Wenn du auf der rechten Seite auf „Zum Fakt springen“ klickst, geht die linke Seite direkt zum entsprechenden Block. Um einen Abschnitt oder ein Wort zu suchen, können Sie die übliche Strg+F-Suchfunktion verwenden.
Um Ihre Änderungen zu speichern, klicken Sie oben rechts auf der Seite auf „Speichern“. Wenn Sie mit der Bearbeitung fertig sind, können Sie neben der Schaltfläche „Speichern“ auf „Überprüfung beenden“ klicken. Sie können nach Abschluss der Überprüfung immer noch Änderungen vornehmen und bearbeiten. Wenn Sie jedoch an einem überprüften Dokument weiterarbeiten möchten, ist es am besten, den Überprüfungsstatus zu entfernen, um den Überblick darüber zu behalten, was abgeschlossen ist. Sie können den Status „Überarbeitet“ mit derselben Schaltfläche wie „Überprüfung abschließen“ in der oberen rechten Ecke entfernen.
Um eine oder mehrere Dateien in einem Datensatz zu löschen, wählen Sie die Dateien aus und klicken Sie auf „Alle ausgewählten löschen“.
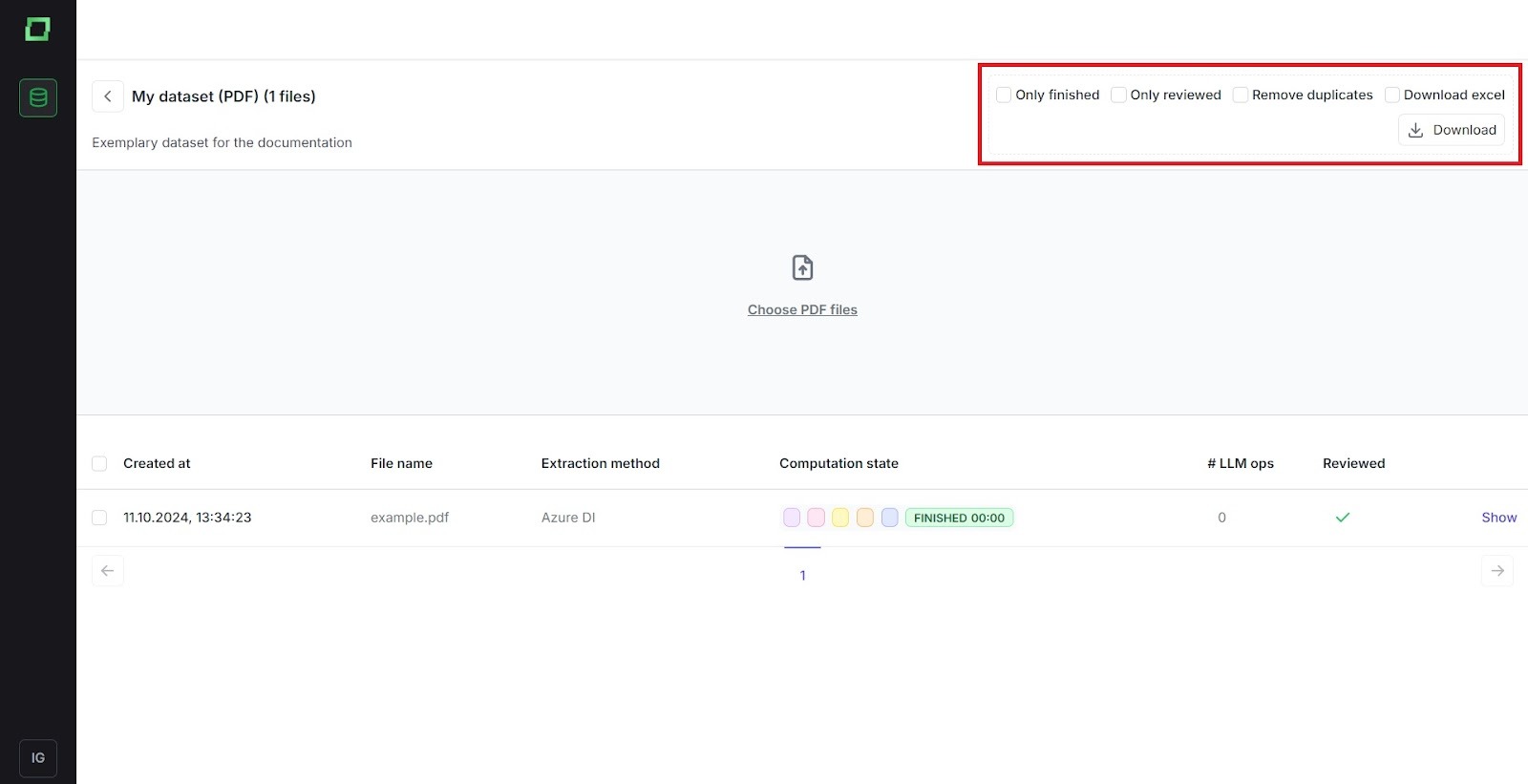
Sie können die Dateien filtern, die Sie herunterladen möchten. Sie können nur fertige Dateien herunterladen (ist in der Pipeline nicht fehlgeschlagen), nur überprüfte Dateien oder beides. Wenn Sie diese Optionen verwenden, werden die Dateien als.csv-Dateien heruntergeladen. Wenn Sie den Filter „Excel herunterladen“ anwenden, werden die Dateien als Excel-Dateien heruntergeladen.
Die Excel-Datei hat zwei Spalten: Name und Inhalt. Jeder Block wird als Zeile unter der Inhaltsspalte dargestellt, wobei der entsprechende Dateiname in der Namensspalte aufgeführt ist. Sie können beim Herunterladen auch Duplikate entfernen.
Lokale OCR-Modelle sind im Allgemeinen nicht so effektiv und präzise wie fortschrittliche cloudbasierte OCR-Lösungen, insbesondere bei der Bewältigung komplexer Datenextraktionsaufgaben. Daher wird in den meisten Fällen dringend empfohlen, die ETL-Pipeline zu verwenden. Lokale OCR-Modelle sollten nur für hochsensible Daten verwendet werden, wenn keine andere Option geeignet ist.
Wir empfehlen, mit Tesseract als primärem lokalen OCR-Modell zu beginnen und dann easyOCR auszuprobieren, wenn Sie eine andere Option erkunden möchten.
Tesseract unterstützt mehrere Sprachen und ist zeiteffizient. Wie bereits erwähnt, sind lokale OCR-Modelle jedoch nicht so präzise wie Cloud-Modelle wie Azure DI. Die bereitgestellte Checkliste gilt weiterhin mit Ausnahme der Blocklänge. Dies wird im Folgenden erklärt.
Verwenden Sie den folgenden Code, um Tesseract auszuführen:
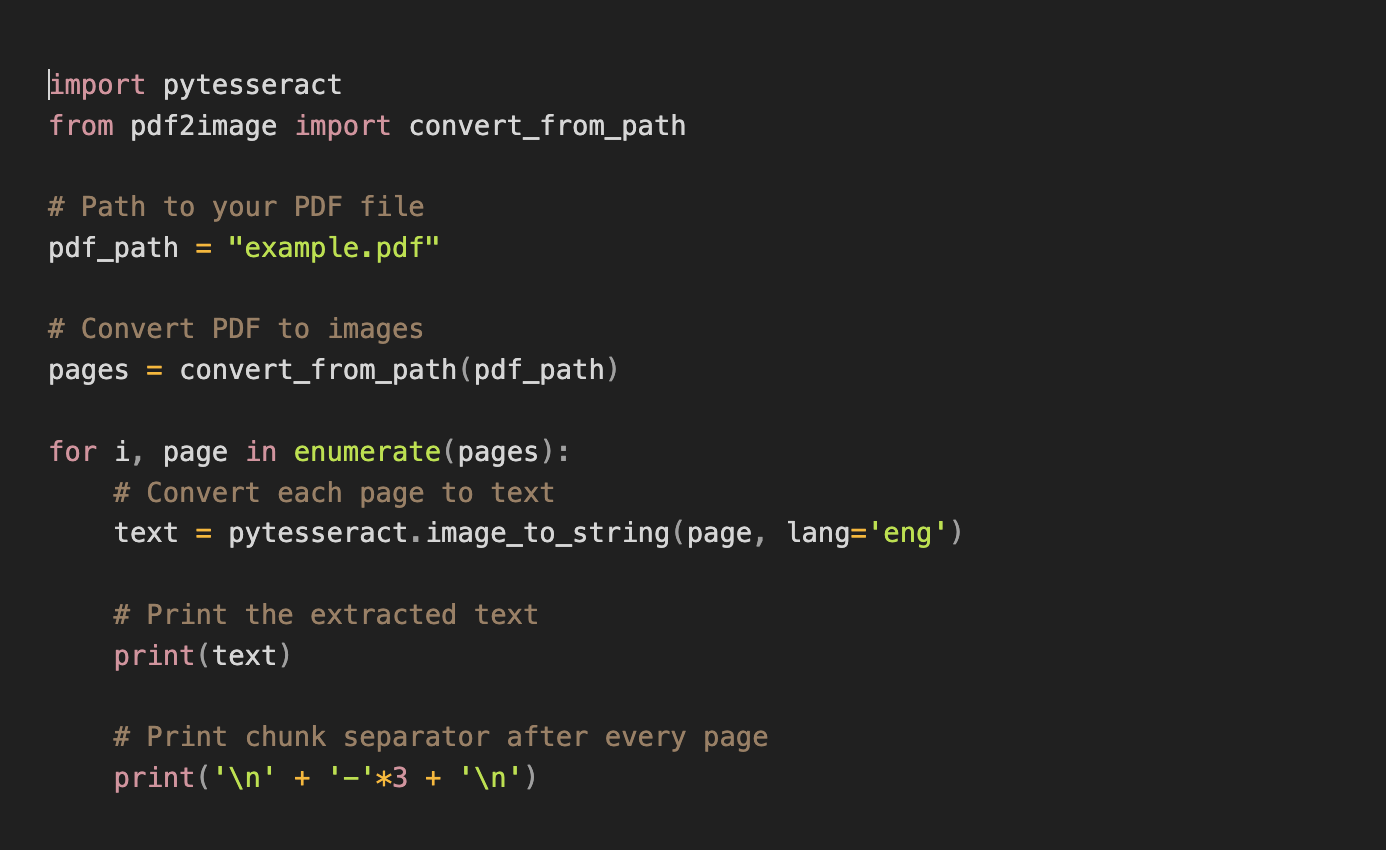
Tesseract und andere lokale OCR-Modelle funktionieren im Allgemeinen mit JPG-Dateien, daher konvertiert dieser Code PDF-Dateien in JPGs.
Der Einfachheit halber ist das Chunking weniger präzise als die ETL-Pipeline. Der Code druckt nach jeder Seite drei Bindestriche aus, was darauf hinweist, dass jede Seite als ein Block behandelt wird.
Wenn Ihr Dokument nicht auf Englisch ist, ändern Sie den Sprachcode in Zeile 12. Die Sprachcodes finden Sie hier https://tesseract-ocr.github.io/tessdoc/Data-Files-in-different-versions.html.
Wenn Sie eine andere Option für Ihr Dokument ausprobieren möchten, können Sie Einfaches OCR. Verwenden Sie den folgenden Code, um es auszuführen:
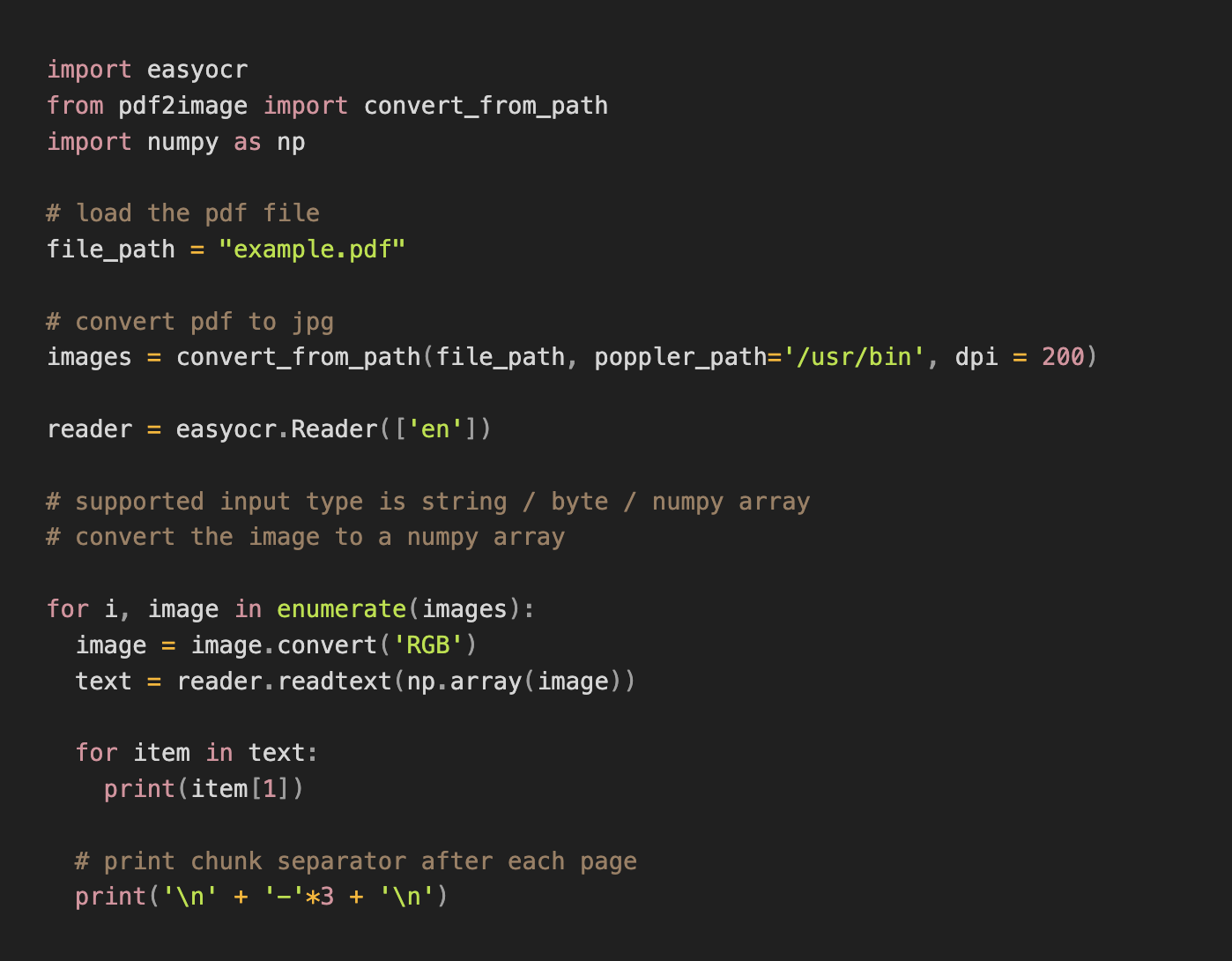
Ändern Sie erneut den Sprachcode in Zeile 11, wenn Ihr Dokument in einer anderen Sprache verfasst ist. Die Sprachcodes finden Sie hier https://jaided.ai/easyocr/ (scrolle nach unten und finde die „Übersicht“).
Um eine bessere Extraktion zu ermöglichen, testen wir verschiedene Methoden, wie das geht. Im letzten Test haben wir GraphRag ausprobiert, einen Ansatz zur Konvertierung von RAG-Dateien in Wissensgraphen. Dieser Ansatz wird noch getestet und befindet sich in der Beta-Version. Sobald wir einen anderen Ansatz verfolgen, wird ein neuer Teil der Dokumentation veröffentlicht.