
Datenmanagement ist ein wesentliches Merkmal der Raffinerie. Sehen Sie hier, wie wir es ermöglichen.
Der Datenbrowser ist das Herzstück des Datenmanagements in Raffinerien. Mit ihm können Sie Labeling-Sessions erstellen, Ihre Daten filtern und überprüfen, ähnliche Datensätze finden und vieles mehr. Lass uns gleich eintauchen!
Eine der Kernfunktionen des Datenbrowsers sind seine umfangreichen Filterfunktionen. Im folgenden Abschnitt wird erklärt, was die verschiedenen Filtertypen sind, wie sie funktionieren und wie sie Sie bei Ihren Kennzeichnungs- und Datenverwaltungsaufgaben unterstützen können.
Egal, ob Sie nach Textmustern suchen oder Ihre Daten einfach nach einem Attribut in Blöcke aufteilen möchten, die Attributfilter bieten eine Vielzahl von Kombinationen, wenn Sie Ihre Daten überprüfen und verwalten möchten. Ein Attributfilter ist eine Kombination aus einem _Attribut_, einem _Operator_, einem _Wert_, einem _Auswahlstatus_ und _operatorspezifischen Optionen_. Die _attribute_-Auswahl ist ein Dropdownmenü, das alle verfügbaren Attribute Ihrer Daten anzeigt, die nicht aktiv ausgeblendet sind (siehe [Attributsichtbarkeit] (/refinery/attribute-visibility)). Diese Auswahl bestimmt das Attribut, auf das der Filter angewendet wird. Dies ist das `headline`-Attribut in Abb. 1. Die _Operator_-Auswahl ist ebenfalls ein Drop-down-Menü, jedoch mit vorkonfigurierten Auswahloptionen. Wir unterstützen derzeit die folgenden Optionen: - `EQUAL`: Prüft die direkte Gleichheit eines Attributs und des angegebenen Werts. Unterscheidet zwischen Groß- und Kleinschreibung. - `BEGINNT MIT`: Prüft, ob das Attribut mit dem angegebenen Wert beginnt. - `ENDET MIT`: Prüft, ob das Attribut mit dem angegebenen Wert endet. - `CONTAINS`: Prüft, ob der angegebene Wert an einer beliebigen Stelle des Attributs mindestens einmal vorkommt. - `IN`: Ähnlich wie EQUAL, aber Sie können eine Liste möglicher Werte angeben, anstatt nur einen. Verwenden Sie das in der [configuration] (/refinery/data-management #configuration) angegebene Trennzeichen (Standard: „,“). - `IN WC`: Ähnlich wie IN, aber Sie können die Platzhaltersyntax in Ihrem Wert verwenden. Die Zeichen „\ *“ und „%“ entsprechen allen Zeichen und beliebig vielen davon, während „\ _“ und „?“ entspricht nur einem einzelnen Zeichen. - `GREATER`: Prüft, ob das Attribut größer als der angegebene Wert ist. Bei Text- und Kategorieattributen erfolgt dies Zeichen für Zeichen, was Sie vielleicht vom Sortieren der Namen in einem Dateisystem kennen. Zum Beispiel „a9" > „a10", weil „a“ = „a“ und „9" > „1". | - `GREATER EQUAL`: Ähnlich wie GREATER, beinhaltet aber auch Attribute, die dem angegebenen Wert entsprechen. - `LESS`: Prüft, ob das Attribut kleiner als der angegebene Wert ist. Text- und Kategorieattribute werden genauso behandelt wie in GREATER. - `LESS EQUAL`: Ähnlich wie LESS, schließt aber auch Attribute ein, die dem angegebenen Wert entsprechen. - `BETWEEN`: Prüft, ob das Attribut GRÖSSER GLEICH als der erste angegebene Wert und WENIGER GLEICH der zweite angegebene Wert ist. Der _Wert_ eines Attributfilters ist die Benutzereingabe, die Sie eingeben, z. B. `Falcons` in Abb. 1. Der _Auswahlstatus_ eines Attributfilters ist der Status der Checkbox ganz links. Derzeit gibt es drei verschiedene Zustände: INCLUDE (blaues Kontrollkästchen), EXCLUDE (rotes Kontrollkästchen) und IGNORE (leeres Kontrollkästchen). INCLUDE und EXCLUDE beziehen sich nicht auf die Aufnahme oder den Ausschluss des Filters selbst, sondern darauf, ob wir die Datensätze ein- oder ausschließen möchten, die unsere Filterbedingung erfüllen. Wenn der Auswahlstatus auf IGNORE gesetzt ist, wird der Filter nicht angewendet. Der gewählte Status in Abb. 1 ist INCLUDE. Der letzte Teil eines Attributfilters besteht aus _operatorspezifischen Optionen_, wobei es sich derzeit nur um die Option zur Berücksichtigung der Groß- und Kleinschreibung handelt. Wir nennen sie operatorspezifisch, weil nicht alle Operatoren sie unterstützen. Die Berücksichtigung der Groß- und Kleinschreibung wird von BEGINS WITH, ENDS WITH und CONTAINS unterstützt.
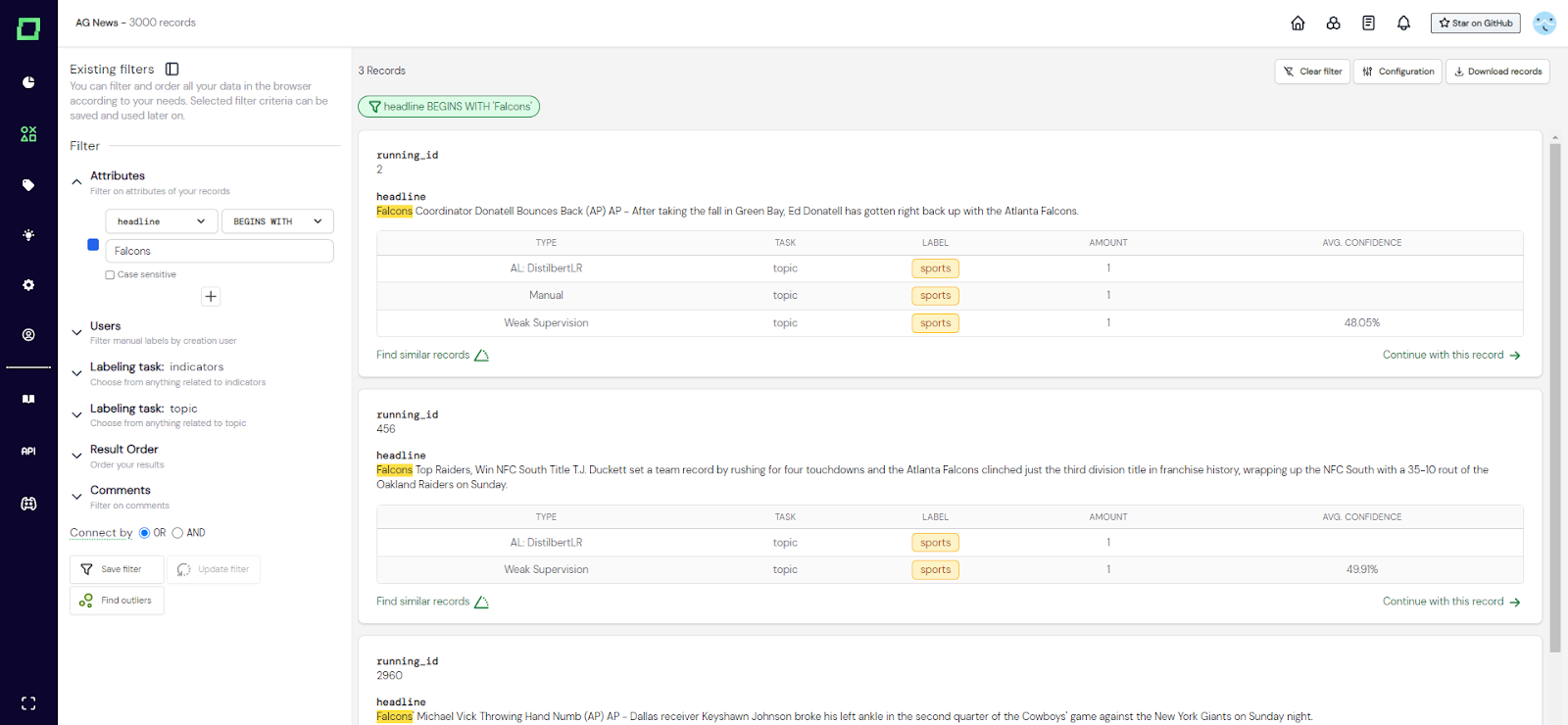
Abb. 1: Screenshot des Datenbrowsers, in dem ein einzelner Attributfilter gesetzt ist. Das erfüllte Filterkriterium ist gelb hervorgehoben (siehe Überschriftenattribut).
In Abb. 1 sehen Sie ein Beispiel für einen Attributfilter. Hier ist das Attribut `headline`, der Operator ist `BEGINNS WITH`, der Wert ist `Falcons`, der Auswahlstatus ist `INCLUDE` (blaue Checkbox) und die operatorspezifische Option „Groß- und Kleinschreibung beachten“ ist nicht ausgewählt.
Möchten Sie mehrere Filter gleichzeitig auf verschiedene Attribute anwenden? Klicken Sie einfach auf das „+“ -Symbol unter Ihrem Attributfilter, um einen neuen Attributfilter hinzuzufügen. Mehrere Filter werden mit UND kombiniert, sodass Sie nach der Schnittmenge von Datensätzen filtern, bei der alle Attributfilter als wahr ausgewertet werden.
Für jede von Ihnen erstellte Beschriftungsaufgabe wird im Datenbrowser automatisch ein eigenes Menü zum Reduzieren des Filters angezeigt. Jeder Aufgabenfilter für die Kennzeichnung enthält die folgenden Optionen: _manuell beschriftet_, _schwach überwacht_, _Model-Callback_ und _heuristics_. Mit dem _manuell beschriftet_ Mehrfachauswahl-Dropdown-Menü können Sie Ihre Daten anhand der manuellen Bezeichnung filtern, die für diese spezielle Beschriftungsaufgabe angegeben wurde. Das Drop-down-Menü mit Mehrfachauswahl zeigt alle verfügbaren Labels (auch wenn sie keinem Datensatz zugewiesen wurden) und eine zusätzliche Option „hat kein Label“ an. Die Labelauswahl hat außerdem drei Status: INCLUDE (blaues Kontrollkästchen), EXCLUDE (rotes Kontrollkästchen) und IGNORE (leeres Kontrollkästchen). Standardmäßig ist alles auf IGNORE gesetzt, weshalb nichts gefiltert wird. Die Option „hat kein Label“ ist eine großartige Möglichkeit, Ihre Daten nach unbeschrifteten Datensätzen zu filtern. Sie hat nur die Status INCLUDE und IGNORE. Mit der Mehrfachauswahlliste _schwach überwacht_ können Sie Ihre Daten auf der Grundlage des Labels [schwache Überwachung] (/refinery/weak-supervision) filtern, das für diese spezielle Kennzeichnungsaufgabe vergeben wurde. Es funktioniert genauso wie das _manuell beschriftet_, allerdings mit dem Zusatz eines Konfidenzintervalls. Sie können die Konfidenzintervallfilterung verwenden, ohne tatsächlich nach einem bestimmten Etikett mit schwacher Überwachung zu filtern. Mit der Mehrfachauswahl-Dropdown-Liste _model callback_ können Sie Ihre Daten auf der Grundlage der Labels [Model Callback] (/refinery/model-callbacks) filtern, die Sie Ihrem Projekt hinzugefügt haben. Sie funktionieren ähnlich wie die schwach überwachte Filteroption. Die Filteroption _Heuristics_ funktioniert etwas anders als die anderen, da sie nicht direkt nach einem Label filtern kann. Stattdessen können Sie eine Reihe von Heuristiken auswählen und nur die Datensätze anzeigen, für die die Heuristiken eine Vorhersage treffen. Dieser Filter hat außerdem die drei Status INCLUDE, EXCLUDE und IGNORE. Der Filter zeigt alle verfügbaren Heuristiken an, auch wenn sie noch nicht ausgeführt wurden. Es gibt eine spezielle Auswahloption namens „Nur mit unterschiedlichen Ergebnissen“, die nach den Datensätzen filtert, bei denen mindestens zwei Heuristiken in ihrer Vorhersage nicht übereinstimmen.
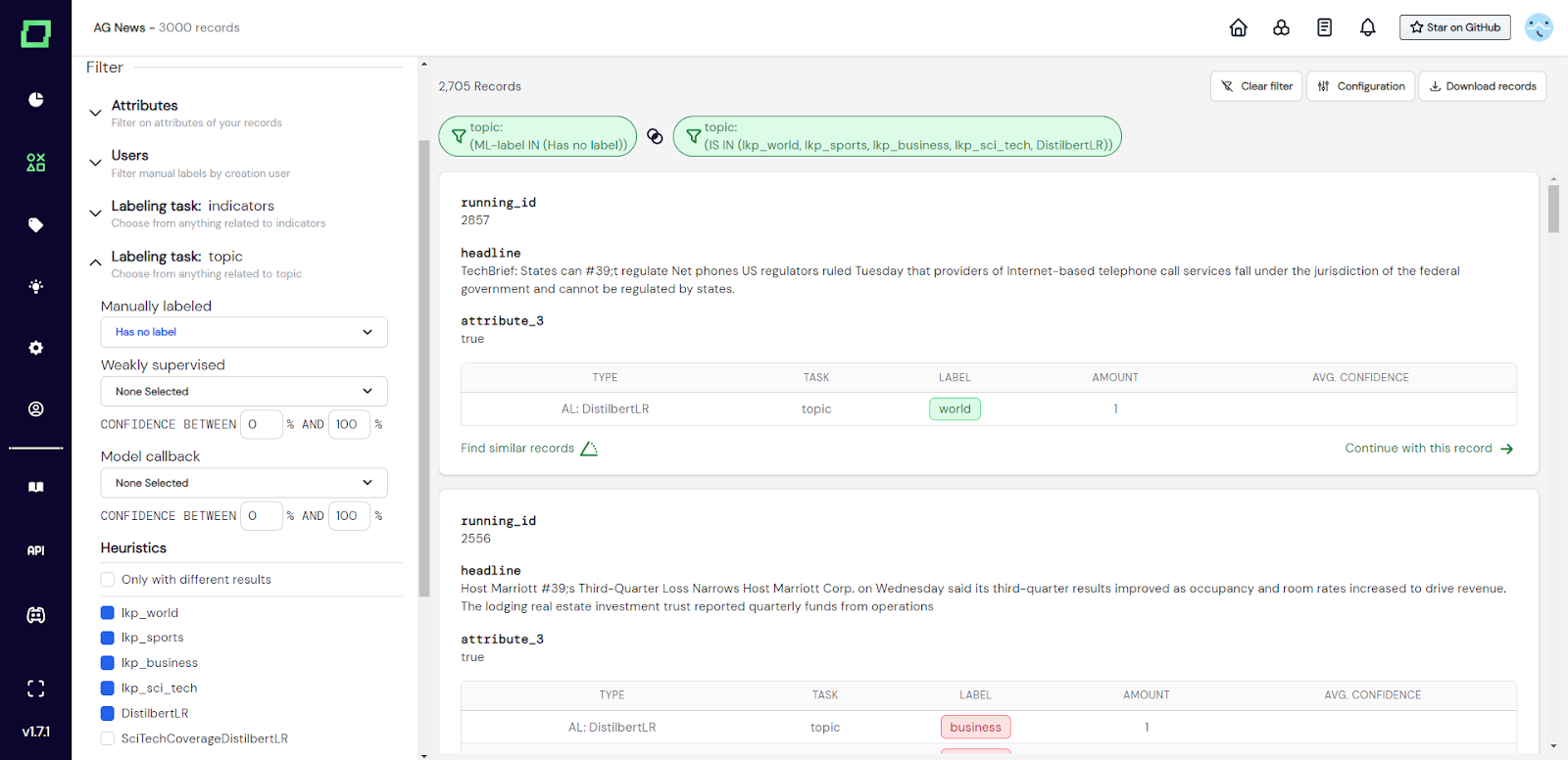
Abb. 2: Screenshot des Datenbrowsers, in dem der Benutzer nach der Klassifikationsbeschriftungsaufgabe „Thema“ gefiltert hat. Diese Filtereinstellung (ausgewählte Heuristiken und keine manuelle Bezeichnung) eignet sich hervorragend für die Validierung von Heuristiken.
Der Kommentarfilter ist sehr einfach. Es gibt eine Option, um nach „Datensätzen mit Kommentaren“ zu filtern. Dies hat auch die drei Status INCLUDE, EXCLUDE und IGNORE, sodass Sie nach Datensätzen filtern können, die Kommentare, keine Kommentare oder einen der beiden haben.
Filteroptionen können beliebig kombiniert werden. Der Kombinationsoperator verschiedener Filtereinstellungen ist das logische UND. Wenn Sie also mehrere Filter auswählen, erhalten Sie die Schnittmenge der Datensätze, die alle Filterkriterien erfüllen. Am Ende der Filteroptionen finden Sie eine Optionsauswahl, der die Worte „connect by“ vorangestellt sind. Diese Auswahl beeinflusst den Kombinationsoperator **nur innerhalb eines Filters**. Das bedeutet, dass der allgemeine Operator immer noch das UND (Schnittpunkt) ist, aber atomare Filteroptionen können ihren Operator so ändern, dass er mit ODER (Vereinigung) verkettet wird. In diesem Moment ändert die Auswahl „Verbinden durch“ das Verhalten der folgenden Filteroptionen: _users_, _manuelled_, _weakly supervised_, _model callback_ und schließlich _heuristics_.
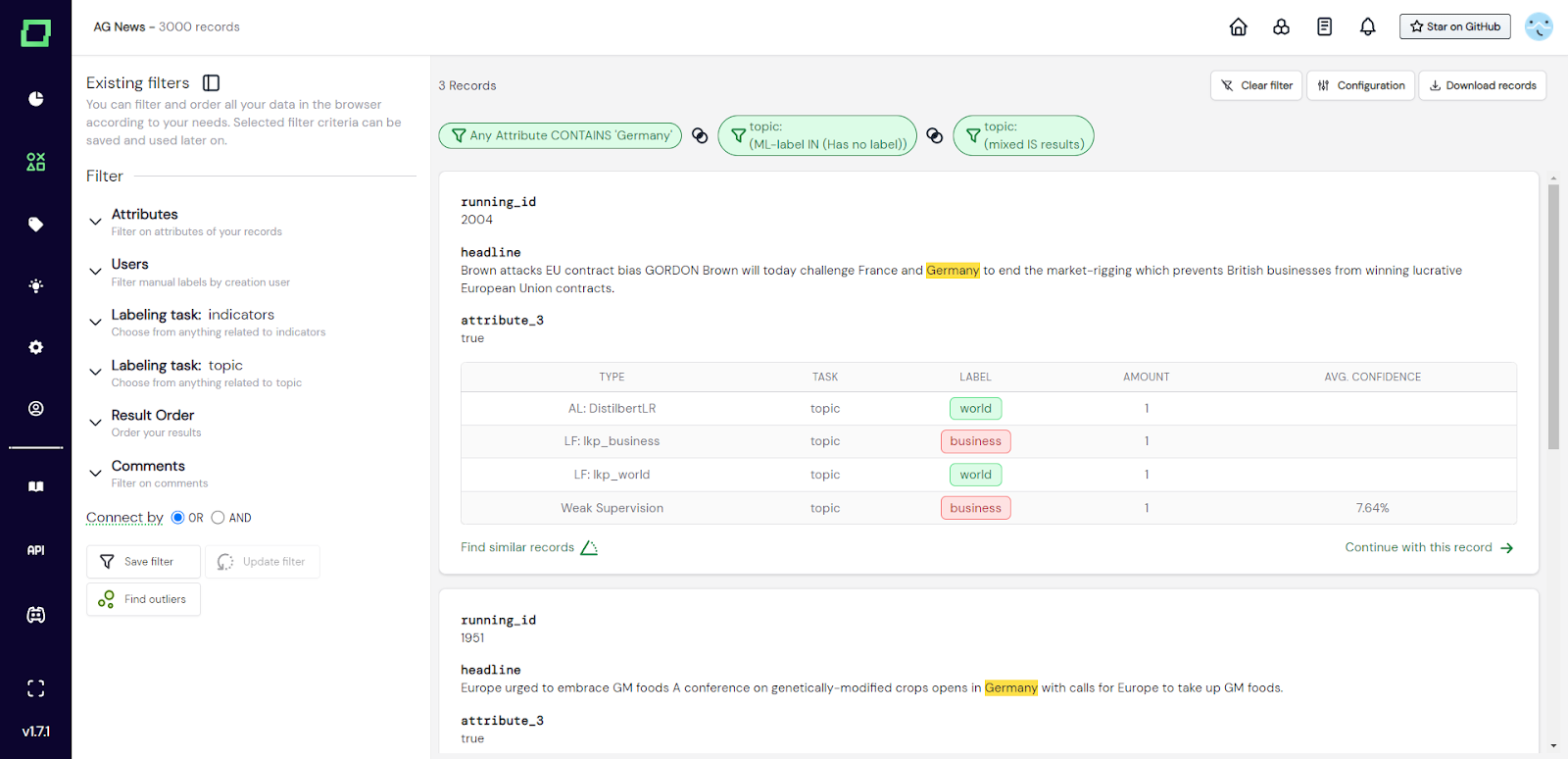
Abb. 3: Screenshot des Datenbrowsers, in dem der Benutzer nach Datensätzen ohne Label gefiltert hat, die Deutschland erwähnen und widersprüchliche Heuristikvorhersagen enthalten.
Filterkombinationen werden nicht automatisch gespeichert. Wenn Sie Ihre Daten filtern und eine Labeling-Sitzung starten oder zu einer anderen Seite navigieren möchten, werden Ihre Filtereinstellungen nicht gespeichert! Wenn Sie diese Einstellungen beibehalten möchten, speichern Sie sie bitte als [Datensegment] (/refinery/data-management #from -filters-to-data-slices).
Da Filter wirklich nützlich sind, um Muster in Ihren Daten zu finden, Beschriftungsarbeiten zu verteilen oder Heuristiken zu validieren, möchten Sie sie natürlich für einen späteren Zugriff speichern. Wenn Sie eine Filtereinstellung speichern, erstellen Sie einen Teil Ihrer Daten, der diese Filterkriterien erfüllt, was wir einfach als „Datensegment“ bezeichnen. In diesem Abschnitt erhalten Sie einen umfassenden Überblick über die verschiedenen Slice-Typen und ihre Funktionsweise in Raffinerien.
Nachdem Sie Ihre Filterkriterien ausgewählt haben, können Sie ein Datensegment erstellen, indem Sie unten in der Filter-Seitenleiste auf die Schaltfläche „Filter speichern“ klicken. Nachdem Sie ausgewählt haben, den Filter zu speichern, erscheint ein Modal, das zwei Eingaben erfordert: den Typ des Datenbereichs und einen eindeutigen Namen dafür. Drücken Sie abschließend auf „Filter speichern“ und das neue Datensegment sollte oben in der Filter-Seitenleiste erscheinen. Neben jedem Datensegment befindet sich ein kleines farbcodiertes Informationssymbol, das den Typ angibt. Sie können auch darauf klicken, um weitere Informationen über das Datensegment zu erhalten, z. B. den vollständigen Namen, das Erstellungsdatum, den Ersteller und den Typ. Wenn Sie ein statisches Datensegment in der [verwalteten Version] (/refinery/managed-version) von Refinery erstellt haben, können Sie dieses Segment auch so betrachten, als ob Sie die Rolle eines Experten hätten, um zu überprüfen, ob es sich um etwas handelt, das Sie einem echten Experten zur Kennzeichnung übergeben möchten.
Abb. 4: Kurzes GIF, das zeigt, wie ein Datensegment im Datenbrowser erstellt wird.
Es gibt zwei Arten von Datensegmenten, die Sie für verschiedene Anwendungsfälle in Betracht ziehen sollten: den _statisch_ und den _dynamischen_ Datenbereich. Der _dynamische_ Datenbereich speichert nur die Filtereinstellungen, mit denen er erstellt wurde. Es hat keinen Status und daher werden die Filter jedes Mal, wenn Sie mit diesem Datensegment arbeiten, erneut auf Ihre Daten angewendet. Wenn Sie also möchten, dass Ihr Datensegment immer auf dem neuesten Stand ist, wählen Sie diese Option. Das Datensegment _static_ speichert dagegen nicht nur die Filterkonfiguration, sondern auch die Datensätze (oder besser gesagt ihre Indizes), die zum Zeitpunkt der Erstellung die Filterkriterien erfüllen. Wenn Sie den Datenbereich später in Ihrem Projekt erneut auswählen, werden nur die gespeicherten Datensätze angezeigt, auch wenn sie möglicherweise nicht mehr den aktuellen Filterkriterien entsprechen. Wenn es jedoch einen Unterschied zwischen _der Anzahl der Datensätze_ gibt, die während der Erstellung gespeichert wurden, und der Anzahl der Datensätze, die zum Zeitpunkt der Auswahl die Filterkriterien erfüllen würden, wird über den Datensegmenten oben in der Filter-Seitenleiste ein kleines dreieckiges Warnzeichen sowie ein Sternchen neben der Anzahl über den einzelnen Datensätzen angezeigt. Zu diesem Zeitpunkt können Sie auswählen, ob Ihr Slice aktualisiert werden soll. Anschließend werden die Datensätze gespeichert, die zu diesem Zeitpunkt die Filterkriterien erfüllen. Wenn Sie Ihre Daten in bestimmten Datensegmenten [überwachen] (Rollen verwalten) möchten, müssen Sie _statische_ Datensegmente verwenden. Aus Effizienzgründen ist die Anzahl der gespeicherten Datensätze in einem statischen Datensegment derzeit auf 10.000 begrenzt.
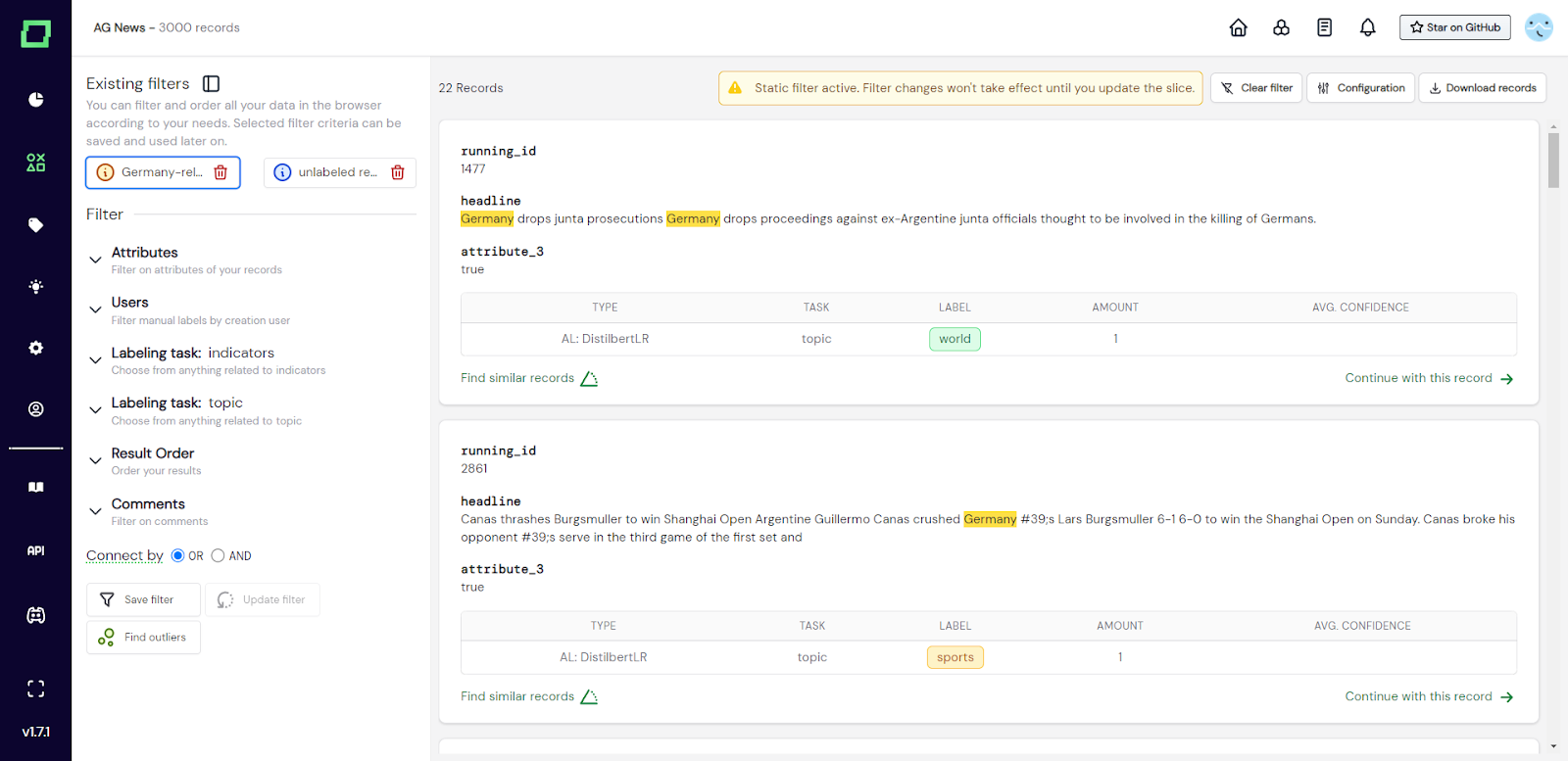
Abb. 5: Screenshot des Datenbrowsers, der derzeit einen statischen (orange) und einen dynamischen (blauen) Datenabschnitt enthält.
Diese Funktion ist der von mehreren Benutzern verwalteten Version der Raffinerie vorbehalten.
Jedem statischen Filter ist eine URL beigefügt, die Sie an Kollegen senden können, die die Experten- oder Annotatorenrolle innehaben. Klicken Sie einfach auf das Infosymbol, klicken Sie auf die URL, um sie in Ihre Zwischenablage zu kopieren, und senden Sie sie schließlich an Ihren Kollegen. Nach dem Einloggen werden sie direkt in der Experten-Labeling-Ansicht angezeigt. Wenn Sie eine Auffrischung des Rollensystems in der Raffinerie benötigen, besuchen Sie die [Rollenverwaltungsseite] (/refinery/managing-roles) in dieser Dokumentation.
Jedes hochgeladene oder verwendbare Attribut Ihrer Daten, das nicht versteckt ist, steht für die Sortierung der Ergebnisse im Datenbrowser zur Verfügung. Darüber hinaus haben Sie die Möglichkeit, nach schwacher Supervision-Konfidenz, Modell-Callback-Konfidenz und nach dem Zufallsprinzip (reproduzierbar dank des Seeds) zu sortieren. Sie können Ihre Ergebnisse aufsteigend oder absteigend sortieren und es gibt keine verschachtelte oder kombinierte Reihenfolge. Sie müssen also ein einzelnes Attribut oder eine einzelne Option auswählen, nach der Sie sortieren möchten.
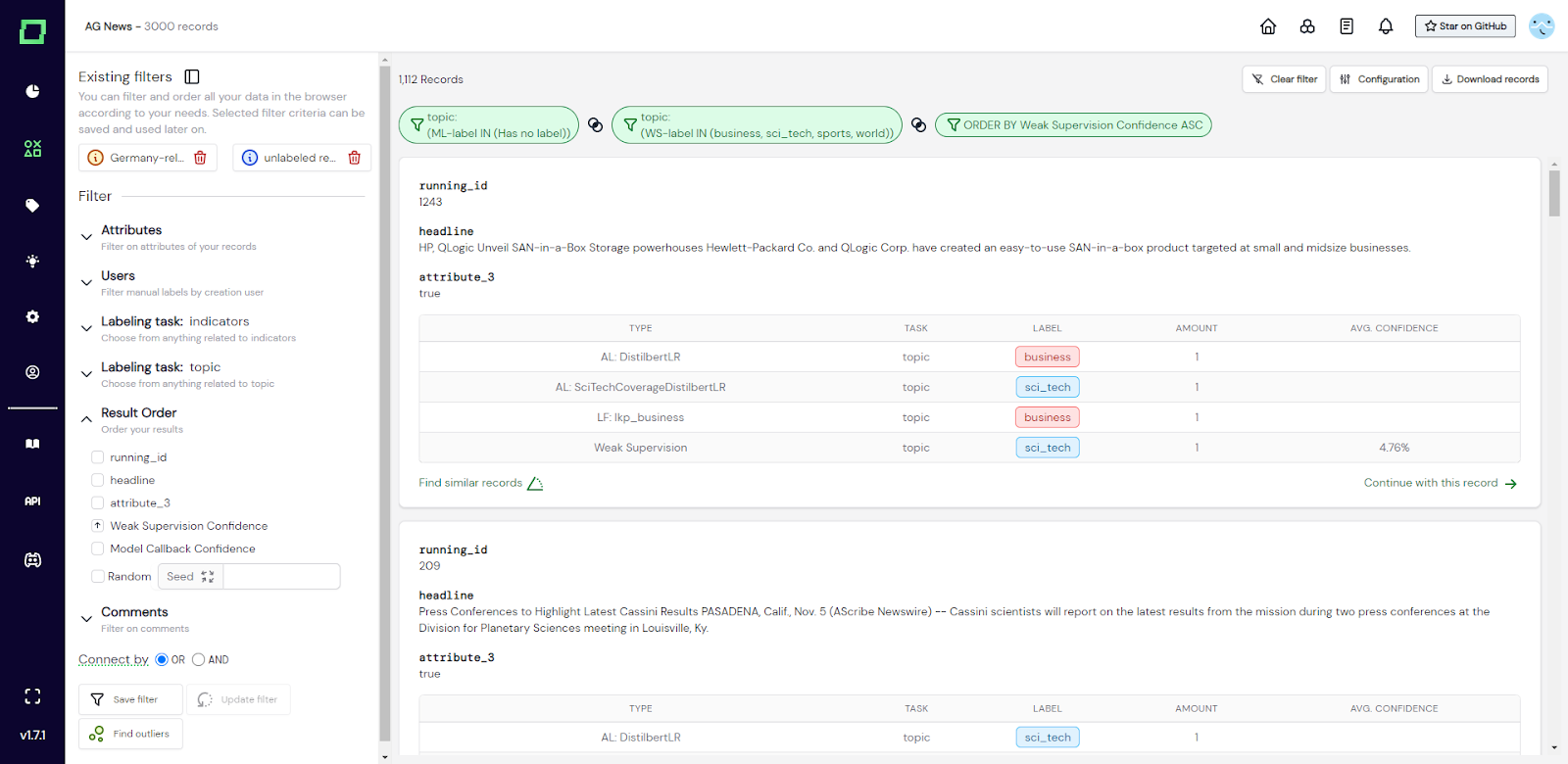
Abb. 6: Screenshot des Datenbrowsers, in dem der Benutzer nach Datensätzen gefiltert hat, die ein schwaches Überwachungslabel und kein manuelles Label haben. Die Datensätze sind nach aufsteigendem, schwachem Vertrauen in die Aufsicht sortiert, um konkrete Klassifizierungsbeispiele für eine manuelle Kennzeichnung zu finden.
Der Datenbrowser integriert die auf Einbettung basierende Ausreißererkennung und Ähnlichkeitssuche. Eine vollständige Dokumentation zu diesen Funktionen finden Sie auf der Seite [neuronale Suche] (/refinery/neural-search).
Es gibt ein paar zusätzliche Einstellungen, die zu viel ins Auge gefallen wären, wenn wir sie direkt in die Benutzeroberfläche integriert hätten. Deshalb werden sie oben rechts im Datenbrowser unter „Konfiguration“ gesammelt. _Text hervorheben_ (standardmäßig aktiviert): Wenn Sie Attributfilter verwenden, haben Sie die Möglichkeit, die passenden Suchbegriffe in Ihren Datensätzen hervorzuheben. Diese Hervorhebung ist für Vergleichsoperatoren wie BETWEEN, GREATER und LESS nicht verfügbar. _Nur schwach überwachte Daten anzeigen_ (Standardeinstellung deaktiviert): Diese Einstellung entscheidet, ob der Datenbrowser alle Prognosen aus Heuristiken für jeden einzelnen Datensatz anzeigt oder nur diejenigen, die in die Berechnung des aktuellen Labels für schwache Überwachung eingeflossen sind. _Sichtbare Zeilenumbrüche (standardmäßig deaktiviert): Diese Einstellung ändert die Anzeige Ihrer Attribute. Wenn diese Option aktiviert ist, zeigen der Datenbrowser und die Beschriftungsseite die Zeilenumbrüche an, die sich in Ihren Textattributen befinden. Wenn diese Option deaktiviert ist, werden Zeilenumbrüche für eine kompaktere Ansicht ignoriert. _IN-Operatorauswahl_ (Standard `,`): Diese Einstellung bestimmt, welches Trennzeichen Sie für den IN-Operator des Attributfilters verwenden. Sie wird meistens nur benötigt, wenn Sie nach etwas suchen möchten, das das aktuelle Trennzeichen enthält. In diesem Fall können Sie es ändern. Verfügbare Optionen sind ein Komma und ein Bindestrich.
Dies ist eine kleine Sammlung von Best Practices, die wir in einem Kennzeichnungsprojekt als nützlich empfunden haben. Wir werden diesen Abschnitt mit der Zeit erweitern, schauen Sie also hin und wieder vorbei, um neue Anregungen zu erhalten!
Sie können auch die für die Etikettierungsaufgabe spezifischen Schubladen verwenden, um mögliche Diskrepanzen bei der Etikettierung zu erkennen. Da Sie nach dem schwachen Wert für das Vertrauen in die Aufsicht sortieren können, können Sie auf diese Weise entweder manuelle Kennzeichnungsfehler (d. h. es liegt eine Diskrepanz vor und das schwach überwachte Etikett hat eine hohe Wahrscheinlichkeit) oder schwache Fehler bei der Überwachung finden.
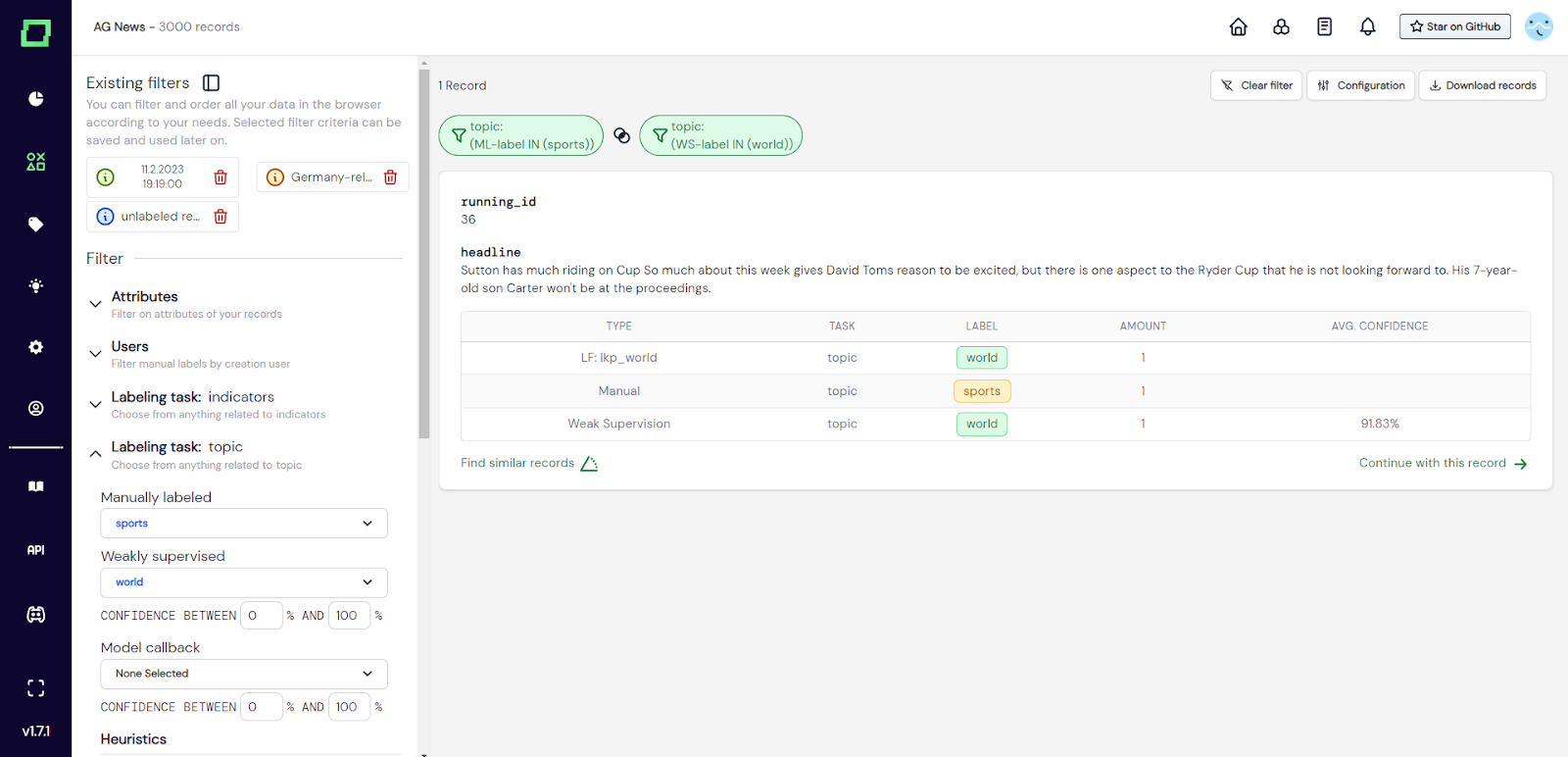
Abb. 7: Screenshot des Datenbrowsers, in dem der Benutzer nach Labelinkongruenzen zwischen schwacher Überwachung und manueller Kennzeichnung sucht.