
Refinery bietet eine Funktion, mit der Benutzer ihre vorhandenen Daten erweitern können, indem sie neue Attribute berechnen. Dies wird erreicht, indem Python-Code geschrieben wird, der die aktuellen Datensätze manipuliert und dabei möglicherweise externe APIs verwendet, um neue Werte für diese hinzugefügten Attribute zu erzeugen und zurückzugeben.
Refinery bietet eine Funktion, mit der Benutzer ihre vorhandenen Daten erweitern können, indem sie neue Attribute berechnen. Dies wird erreicht, indem Python-Code geschrieben wird, der die aktuellen Datensätze manipuliert und dabei möglicherweise externe APIs verwendet, um neue Werte für diese hinzugefügten Attribute zu erzeugen und zurückzugeben.
Refinery ermöglicht es Ihnen, neue Attribute für Ihre bereits vorhandenen Daten zu berechnen. Das bedeutet, dass Sie Python-Code schreiben können, der Ihren vorhandenen Datensatz als Eingabe verwendet, einige Transformationen durchführt oder außerhalb von APIs verwendet und schließlich einen Wert zurückgibt, der der Wert für dieses neue Attribut ist. Die Attributberechnung wird auf jeden Datensatz einzeln angewendet.
Wir sind der festen Überzeugung, dass eine gute Kennzeichnungsumgebung so flexibel wie möglich sein muss, um mit den sich ändernden Anforderungen Schritt zu halten. Eines dieser Tools, das mehr Flexibilität ermöglicht, ist die Berechnung neuer Attribute, während das Projekt bereits läuft. Dies ist in vielen Szenarien nützlich, hier sind zwei Beispiele: - Sie entwickeln dieselben Funktionen in vielen Ihrer Labeling-Funktionen, also entscheiden Sie sich, den Code zu nehmen und ihn als neues Attribut hinzuzufügen, was Ihnen in einem schwachen Überwachungszyklus viel Rechenaufwand erspart. - Beim Labeling stellen Sie fest, dass ein nützlicher Prädiktor die Stimmung eines bestimmten Textes sein könnte. Sie beschließen, Ihren Daten ein neues Attribut hinzuzufügen, das Ihre Datensätze mit einem Stimmungswert aus einer Remote-API anreichert, die Sie kennen und der Sie vertrauen. Weitere Anregungen finden Sie in unserer Inhaltsbibliothek mit dem Namen [bricks] (https://bricks.kern.ai/home), in der wir häufig verwendete NLP-Anreicherungen wie Obszönitätserkennung, E-Mail-Extraktion, Sprachübersetzung und vieles mehr gesammelt haben. Sie sind alle in Python geschrieben und so konzipiert, dass sie direkt in die Raffinerie kopiert werden können.
Um Ihren Daten ein neues Attribut hinzuzufügen, müssen Sie die Einstellungsseite aufrufen und auf die Schaltfläche „Neues Attribut hinzufügen“ klicken (siehe Abb.1).
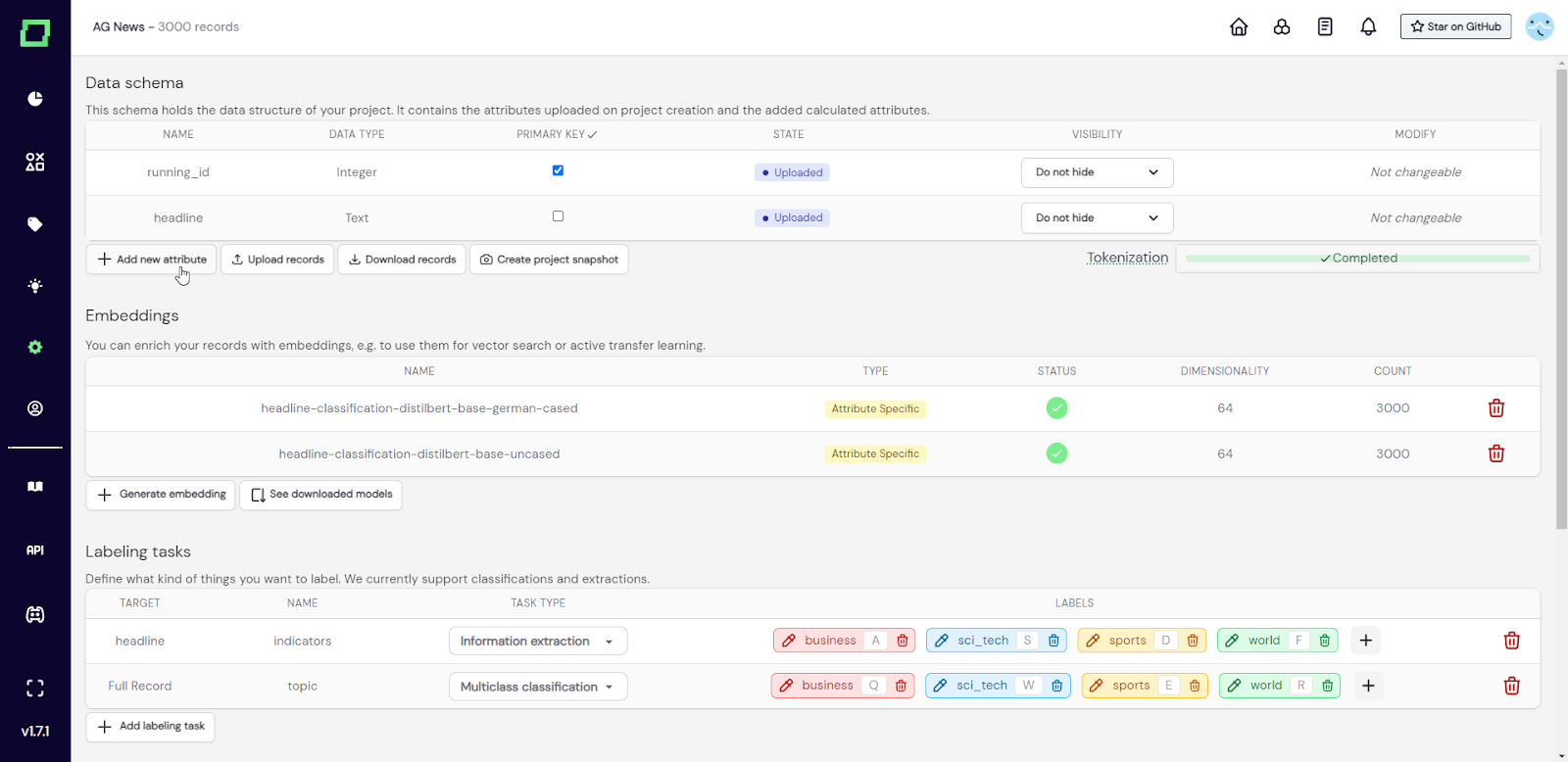
Abb. 1: Screenshot der Einstellungsseite, auf der der Benutzer ein neues Attribut hinzufügen möchte.
Danach erscheint ein Modal (siehe Abb. 2), das Sie auffordert, einen neuen eindeutigen Attributnamen und den Datentyp dieses neuen Attributs einzugeben.
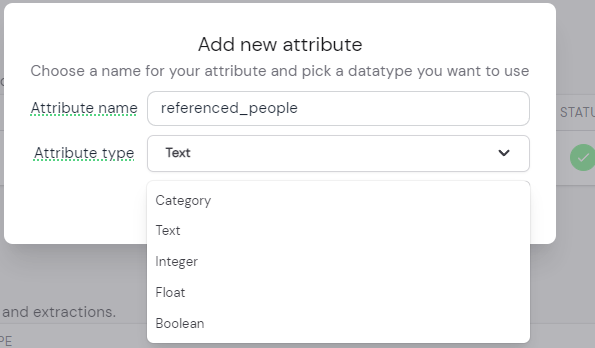
Abb. 2: Screenshot des Modals, das nach dem Klicken auf „Neues Attribut hinzufügen“ erscheint.
Für die Tokenisierung und Einbettung stehen nur `Text`-Attribute zur Verfügung. Der Attributdatentyp dient als Schutz für Ihr berechnetes Attribut, da die Berechnung einen Fehler auslöst, wenn der zurückgegebene Wert nicht dem angegebenen Datentyp entspricht. Außerdem wird der Datentyp im Datenbrowser berücksichtigt, sodass für jeden Datentyp unterschiedliche Filteroptionen zur Verfügung stehen. Beispielsweise kann ein Attribut des booleschen Datentyps nur während der Filterung ein- oder ausgeschaltet werden, es gibt keine zusätzlichen Optionen dafür. Wenn Sie mehr über die Auswirkungen der Auswahl der Datentypen erfahren möchten, lesen Sie bitte den Abschnitt über [Attributfilter] (/refinery/data-management #attribute -filters).
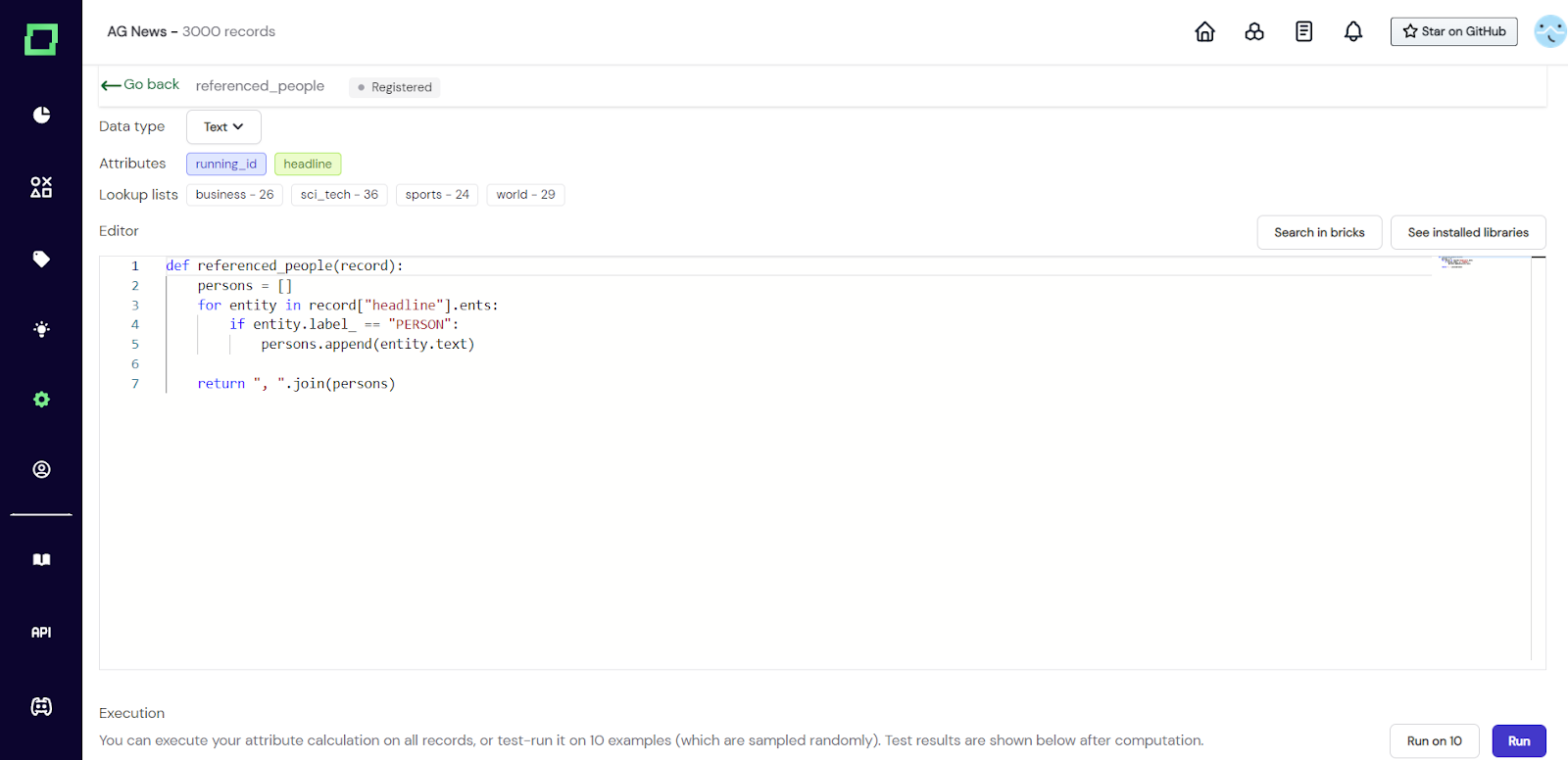
Abb. 3: Screenshot einer Attributberechnungsfunktion, die ein neues Attribut hinzufügt. Dabei handelt es sich um eine Liste von Personen, auf die im Attribut 'Überschrift' verwiesen wird. Beachten Sie, dass diese Funktion noch nicht ausgeführt wurde und daher oben neben ihrem Namen der Status „Registriert“ angezeigt wird.
Nach dem Erstellen der Funktion werden wir von der üblichen Oberfläche begrüßt, die Sie von den [Labeling-Funktionen] (/refinery/building-labeling-functions) kennen sollten. Die Eingabe, die Sie erhalten, ist immer noch ein einziger Datensatz, der wie ein Wörterbuch behandelt werden kann, wobei jedes Textattribut vom Typ `SPacy Doc` ist (siehe [ihre Dokumentation] (https://spacy.io/api/doc)). Deshalb können wir die Entitäten des Attributs „headline“, die während des Tokenisierungsprozesses extrahiert wurden, iterieren. Sie können Anfragen in Ihrer Attributberechnung verwenden. Wenn Sie Ihre Datensätze mit einer externen oder lokal laufenden API anreichern möchten, können Sie das Python-Paket [requests] (https://pypi.org/project/requests/) in Ihrer Attributberechnungsfunktion verwenden.
Nachdem Sie Ihr Attribut in der Funktion zusammengestellt haben, müssen Sie es nur noch zurückgeben. Stellen Sie sicher, dass der Datentyp dem von Ihnen angegebenen entspricht, da Sie sonst eine Fehlermeldung erhalten. Es empfiehlt sich, die Funktion „Auf 10 ausführen“ zu verwenden, bevor Sie mit der Attributberechnung beginnen, da dadurch in der Regel alle Fehler behoben werden. Wenn alles abgeschlossen ist und Sie Ihre Funktion getestet haben, können Sie in der unteren rechten Ecke auf „Ausführen“ klicken. Dadurch wird die Funktion zur Attributberechnung für Ihre gesamten Daten ausgeführt. Bitte beachten Sie, dass dieses berechnete Attribut nach der Ausführung unveränderlich ist. Wenn Sie also etwas anpassen müssen, müssen Sie ein neues Attribut erstellen und den alten Code kopieren.
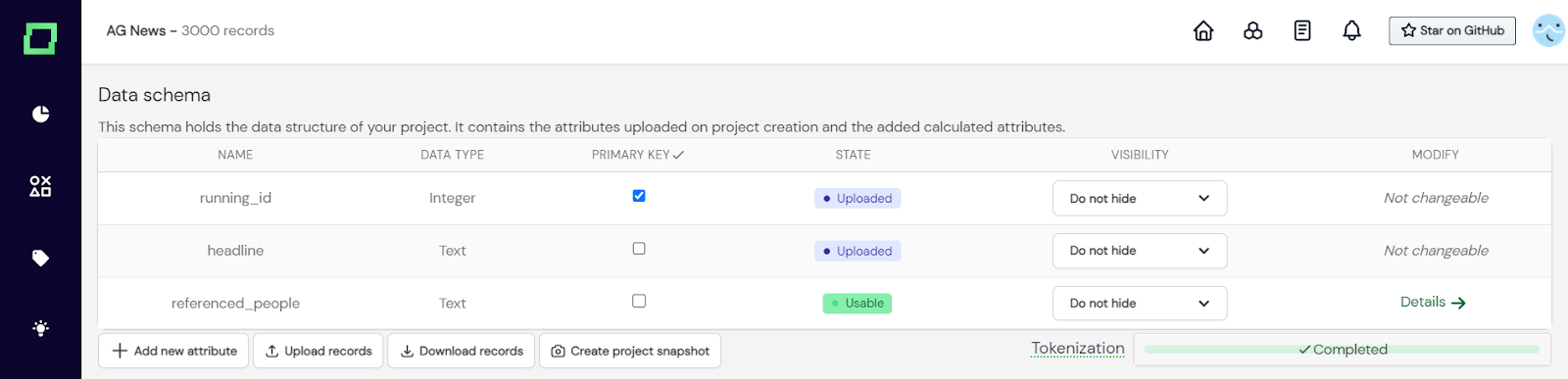
Abb. 4: Nach der Ausführung ist das neue Attribut nun unveränderlich und befindet sich im Zustand 'verwendbar'.
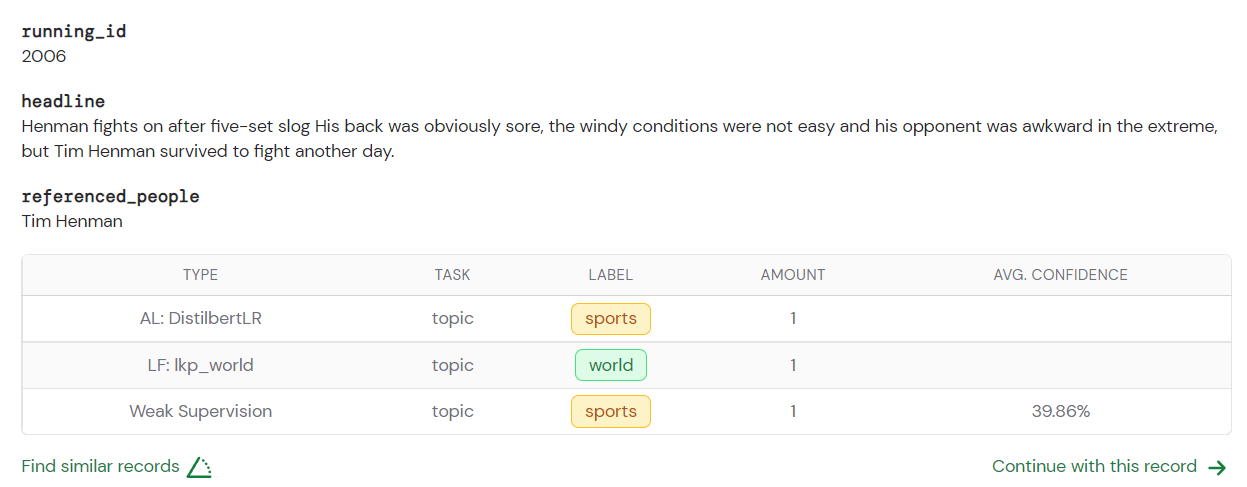
Abb. 5: Ein Screenshot eines Datensatzes im Datenbrowser, in dem wir das neu hinzugefügte Attribut sehen können.